【AWS re:Invent 2024レポート】Amazon Bedrock Guardrailsの自動推論チェックを使用して生成AIアプリケーションの品質と安全性を確保する
2025年3月6日 井上 奈々 Nana Inoue(詳しく見る)

DXアプリケーション担当の井上です。データ分析の集計機能開発、集計結果をグラフや表などでダッシュボードに表示させる機能の設計、開発、テストを行っています。
ラスベガスで開催された「AWS re:Invent 2024」にて、生成AIを中心に様々なセッションに参加してきました。その中から、Amazon Bedrock
Guardrailsの自動推論チェックを利用し、健全で正確な生成AIアプリケーションの構築に関するセッションから、自動推論とは何なのか・自動推論チェックがどのように有意義なのか等、説明を交えてご紹介します。
セッション
タイトル: Introducing automated reasoning checks in Amazon Bedrock Guardrails
(AIM393-NEW)
・登壇者:Stefano Buliani, Byron Cook
・概要: Amazon Bedrock Guardrailsの自動推論チェックが、健全で責任ある生成AIアプリケーションの構築にどのように役立つかを学ぶ。
早速ですが皆さん、生成AIアプリケーションを使用したことはありますか?
自動翻訳ツール、カスタマーサポートでのチャットボット、画像生成ツール等、日常的に使われている様々な生成AIアプリケーションがあり、これらはとても便利です。
ただ、使用する中で“なんだか変な回答だな”、“この内容は本当に合っているのかな”、“違和感がある”などと感じたことはありませんか?
実際に私もそう感じたことがありますし、生成AIによる回答が必ずしも正しいとは限らないことは周知の事実となっています。
そういった、生成AIが事実に基づかない情報を生成する現象のことを「ハルシネーション」といいます。
これは生成AI領域において最大の懸念点とされており、本セッションによると、調査対象であるCIOの約9割以上が、顧客サポートや生産性の向上等にあたり生成AIが重要な役割を果たすと考えている一方で、「ハルシネーション」を解決する必要があると回答した人の割合も増大しており、その懸念は年々高まっています。
実際、Stefano
Buliani(AWSのプロダクトマネージャー)がLLM(大規模言語モデル)を使用したシステムのテストを実施した時、そのシステムは機能しましたが確実ではありませんでした。どのように確実ではなかったのか、実際に確認してみましょう。

図1 Stefano Buliani がテストに用いた原文(左)とLLMの回答(右)
あるテキストの一部を切り出し、LLMにそれを一文で要約するように依頼しました。
原文(図1 左)
友達のサムと私はAdvent of
Codeのパズルを解くのを楽しんでいます。問題を解くためにどのアルゴリズムを使うか、Slackで何時間も議論しています。この活動に対する情熱が、私たちをより良い友達にしてくれています。
LLMの回答(図1右)
ベンと私はAdvent of codeのパズルを解くのが大好きで、その活動が私たちを良い友達にしています。
LLMは、2人がコードパズルを解くのが大好きでそれによって良い関係を築いているという事実を見事に捉えました。素晴らしいです。ですが微妙な間違いがあります。
友達の名前が、原文では「サム」、LLMの回答では「ベン」となっています。
正確さが必要な場面である場合は致命的なミスになる可能性があります。
「ハルシネーション」があるからこそLLMを創造的にするのだと登壇者であるStefano
Bulianiは言いますが、最終的には曖昧で複雑な決定をLLMに任せることができれば理想だとも言います。創造性は必要だが、事実を正しく引用するのが理想であるという事です。
このことから、AWSはAmazon Bedrock
Guardrailsに自動推論チェックを取り入れました。自動推論チェックが、生成AIの「ハルシネーション」を減少させてくれるのです。
では、 Amazon Bedrock Guardrailsの自動推論チェックを使用することでどのように「ハルシネーション」を減少させることができるのかをご紹介します。

図2 Amazon Bedrock Guardrailsに備わっている機能
Amazon Bedrock Guardrailsは、生成AIアプリケーションの安全性や品質を管理するためのツールとしてあらゆる点を網羅しています。
・アプリケーションに対するプロンプトインジェクションや攻撃を防ぐ
・LLMが応答することを許可しないトピックを定義できる
・プロンプト及び出力からPII(個人を特定できる情報)と機密情報を削除できる
・コンテキストグラウンディングチェックやその他の機能を使用して、LLMが生成した応答の根拠と関連性を検出することにより、ハルシネーションをフィルタリングする
ここに自動推論チェックが組み込まれたことにより、LLMの応答の正確さを識別するのに役立ち、責任あるAIアプリケーションを構築することが可能になります。
では、自動推論は裏側でどのように機能するのでしょうか。
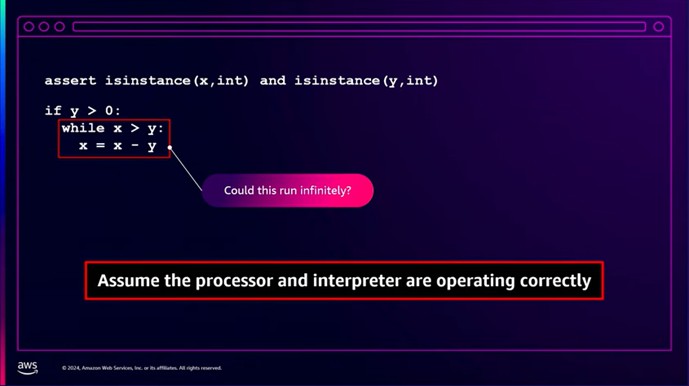
図3 Pythonコード
図3左上にPythonで書かれたコードがありますが、ループが無限に実行されるようなxとyの値は存在するでしょうか。少し考えてみます。
私たちが今考えたことが推論にあたります。
この問題の解答としては、xとyの値が何であれ無限ループにはなりません。
ループを繰り返すたびに「x-y」の値は減少していき、最終的にはxがyを超えなくなる為ループは終了します。
ではなぜ、「x-y」の値は常に減少するのでしょうか。
それは、yが常に正の数で一定である為です。
ではなぜ、yは常に正の数で一定なのでしょうか・・・と、このように事実と根拠を基に推論し、私たちは結論を導き出します。
自動推論というのは、これらの思考をアルゴリズムによって生成します。
コンピュータが与えられた論理的な問題に対して、推論規則を使って解答を導き出します。
つまり、人間が行うような推論(論理的な思考)を自動で実行してくれる、とても便利な機能なのです。
概念こそ違うものの、数理論理学に根差しているという点でシンボリックAI(知識を「記号」として扱い、それらの記号間の論理的な関係を基に推論を行うもの。)と密接に関連しています。
今、私たちが考えられるすべてのxとyを列挙することは現実的ではありませんし、ほぼ不可能といって良いでしょう。
いくつかのシンボル(記号)を少し動かすだけで、私たちが何千年もかけてできるような事をミリ秒単位で見せることができるのが、シンボリックAIや自動推論の魔法なのです。
よってAWSは、自動推論には大きな可能性があると考えています。
では、どのようなアルゴリズムによって自動推論がなされているのかを、ほんの少しだけご紹介します。

図4 数理論理/集合論における意味論
左が図3のコードに行数を振ったもの、右下が数理論理/集合論におけるコードのループの意味論です。
Rは関係(relation)、sが前状態、tが事後状態を表し、pがどの行にいるかを表しています。
1行目でいうと、
コードの1行目にいる「s(p)=1」、かつyが0より大きい「s(y)>0」場合⇒2行目に移動する「t(p)=2」、かつyの値は変わらない「s(y)=t(y)」、かつxの値も変わらない「s(x)=t(x)」。
という意味になります。
ここから先の数式は省略させていただきますが、このような集合論の数式を用いた計算方法を実施していくことで、最終的にはxとyの初期値が何であれいずれループが終了することが証明できます。
これはSMT(Satisfiability Modulo Theories Solvers)と呼ばれ、AWSではよく使われている技法です。
これらの数式を取得して完全自動的に答えてくれる既成のツールがあり、AWSはそれらを使用する内部サービスを利用してプログラムを推論しています。
AWSはこの技術を10年以上使用しており、AWS内で使用する多くのプログラムの正確性を証明しているため、全てのAWSサービスが何らかの形で自動推論の恩恵を受けているのです。
このように自動推論が、生成AIによる応答の正否を論理的な推論のもと、検証してくれるのですね。
では、私たちがAmazon Bedrock
Guardrailsの自動推論チェックを使用する方法を、生成AIアプリケーションを構築することになったと仮定してご紹介します。
一般的に、会社のポリシーやルールが記載された資料はとても長く、しっかりと読むのも必要な情報を見つけ出すのも一苦労です。
そこで、それらを全て理解し、正確に引用してくれるチャットボットを作成することになったと仮定します。
今回は、この人事ポリシーを含むドキュメントを使用します。

図5 あるドキュメントから抜粋した人事ポリシー
翻訳:10年以上の勤続年数で、シニアレベル以上または副社長レベル以上の従業員は、最大1年間の前払い有給休暇(LoA)を取得することができます。
まずはAmazon Bedrockコンソール上の「Automated Reasoning(自動推論)」を選択し、「Create
Policy(ポリシーの作成)」を選択します。
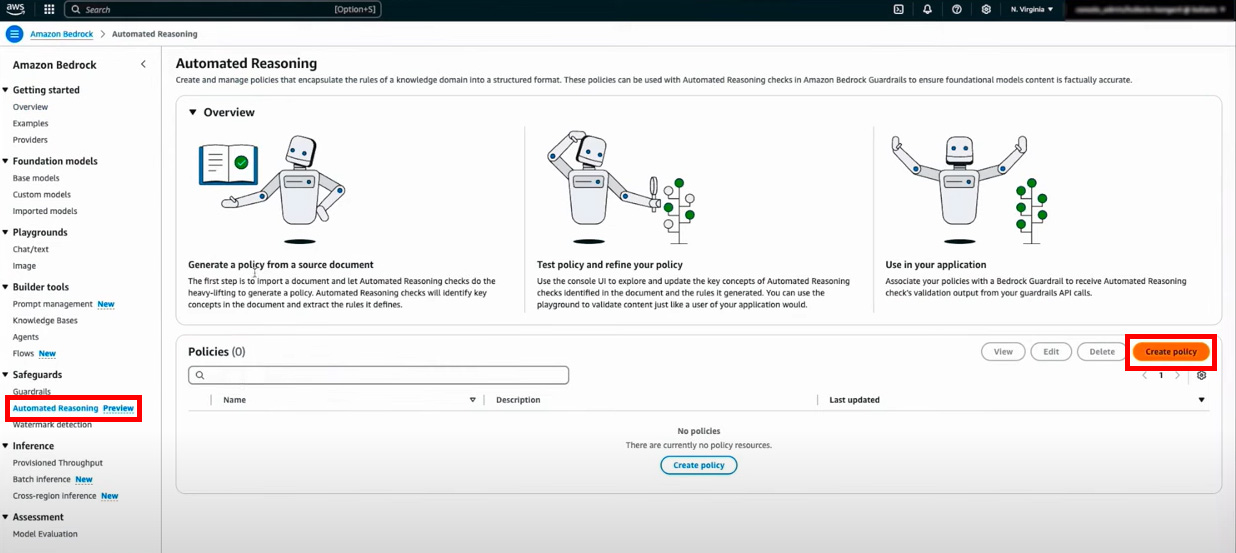
図6 Amazon Bedrockコンソール
ここでは自動推論ポリシーを作成します。
自動推論ポリシーとは、生成AI(LLM等)の応答が正確で、ポリシーに準じているかどうかを確認・検証するためのルールセットです。
ポリシー名を入力し、対象のドキュメントをアップロードします。
「Intent」には、アップロードしたドキュメントをどう使うかのヒントを与えることができます。
画面右下の「Create Policy」押下で、自動推論ポリシーの作成が開始されます。
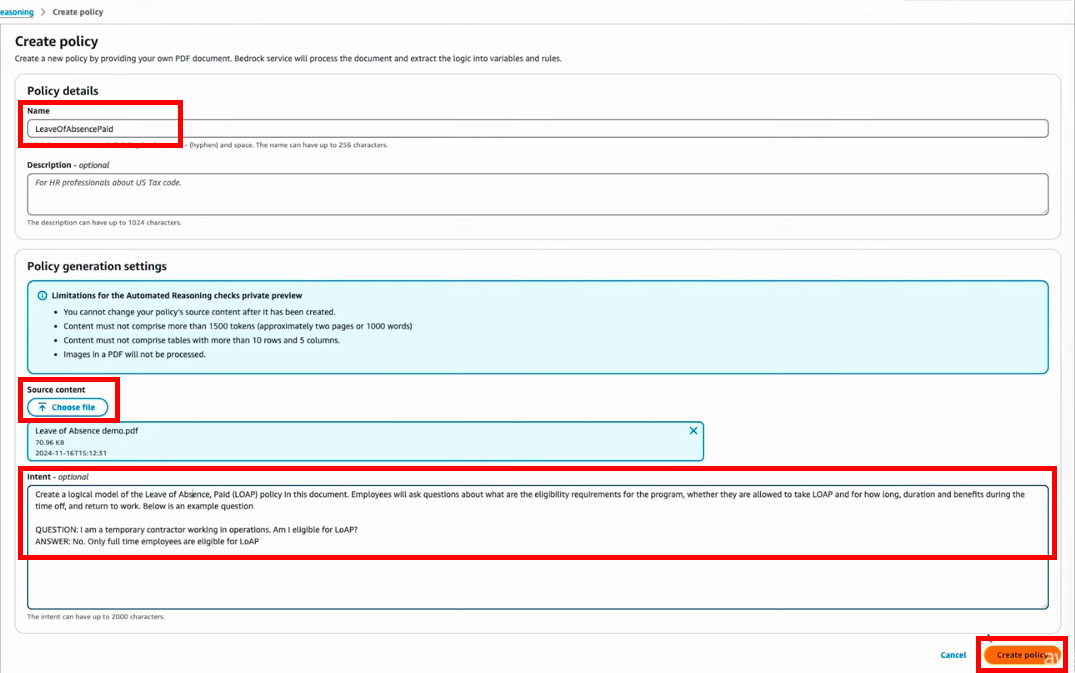
図7 自動推論ポリシー作成画面
今回、「Intent」に入力されている内容は下記のとおりです。
“この文書に基づいて、Leave of Advance, Paid (LOAP)
ポリシーの論理モデルを作成してください。従業員は、適用条件、LOAPの取得可否、取得期間、休暇中の給料、または仕事に戻る条件などについて質問することがあります。
以下は例となる質問です。
質問:「私はオペレーション部門で働いている契約社員です。LOAPの取得対象となりますか?」
回答:「いいえ。LOAPの取得対象はフルタイム社員のみです。」“
自動推論ポリシーの作成が開始されると、バックグラウンドでドキュメント内の重要な単語を特定し、決定木を構築します。
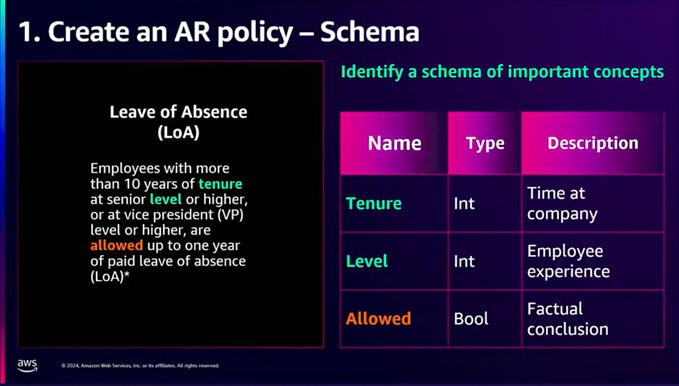
図8 ドキュメントから、重要であろう単語をピックアップしている
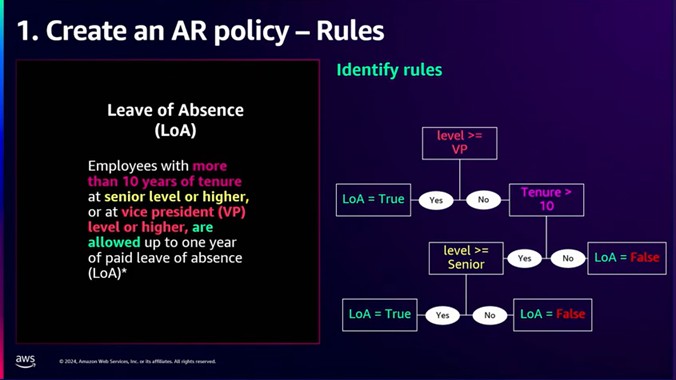
図9 決定木の構築
処理が完了すると、抽出されたルールのリスト、及び作成された変数スキーマが表示されます。
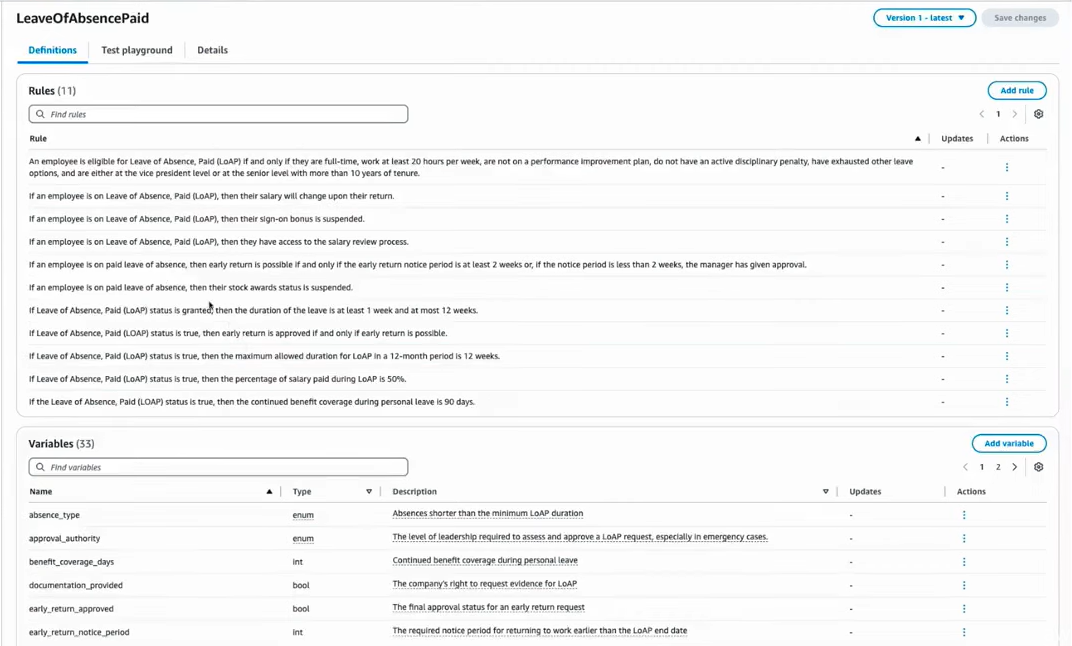
図10 上部「Rules」が抽出されたルールのリスト、下部「Variables」が変数名・その説明等
ユーザーは「Add variable」から新しい変数の追加、「Actions」からルール・変数を編集、削除することが可能です。
「Test playground」タブでは、抽出された内容が正しいかどうかをQAによって確かめることができます。
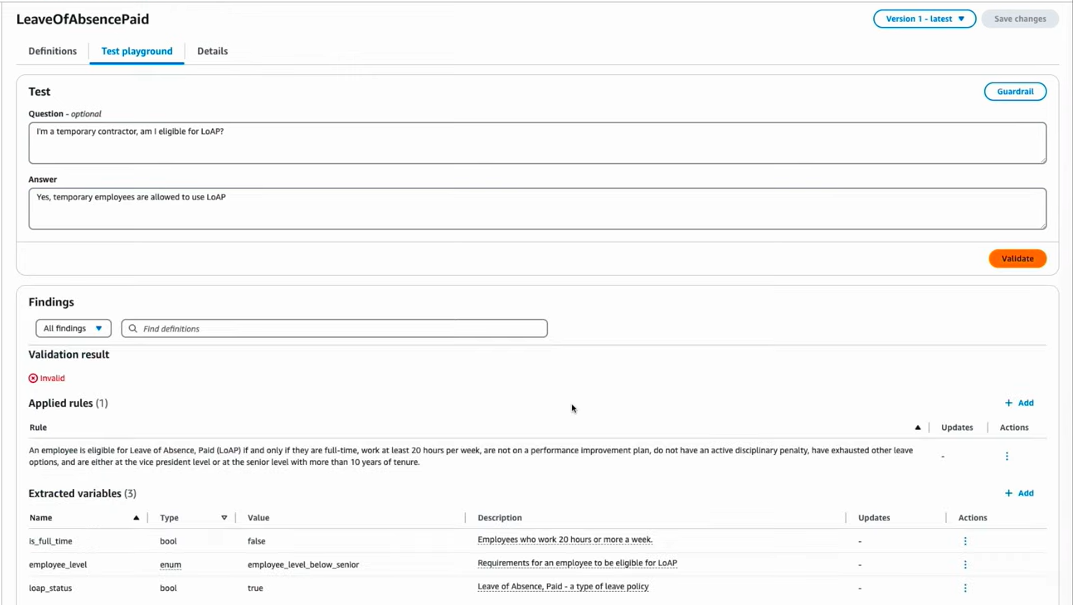
図11 Test playgroundタブ
図11では、
“Q:私は一時的な請負業者ですが、LOAPの取得対象ですか?
A:はい、請負業者はLOAPの取得対象です。“
という間違った回答を入力してテストを実施したため、ルールに違反していて無効だという結果が画面下部に表示されています。
請負社員は従業員ではないので、LOAP取得対象でないという判断結果は正しいですね。
ただ気になるのは、“上級社員ではない”という事もLOAPの取得対象外である要因の一つとして結果に表示されているのです。その事についてはQAで述べられていません。
おそらく、“請負社員だ“と入力したことに基づいてそのような前提を立てたのだと思われますが、明言していないことを仮定してしまうのは望ましくありません。
そのような場合、対象の変数(今回は「employee_level」)を編集し、「仮定はしないでください」と明確に指示することができます。
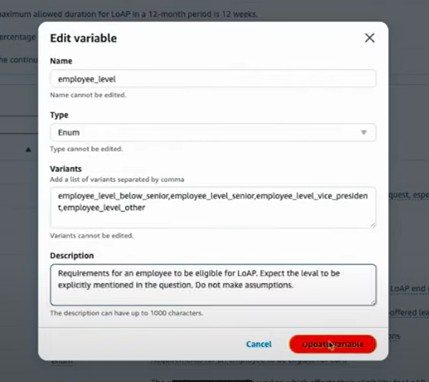
図12 変数の編集
このようにして違和感のある個所は修正し、自動推論ポリシーの作成が完了したら、後はそのポリシーを使用してAmazon Bedrock
Guardrailsを作成します。
その際、新しい機能である「Automated
Reasoning(自動推論)」を有効にすることによって、生成AIの応答がポリシーに準じているかを検証してくれることになります。
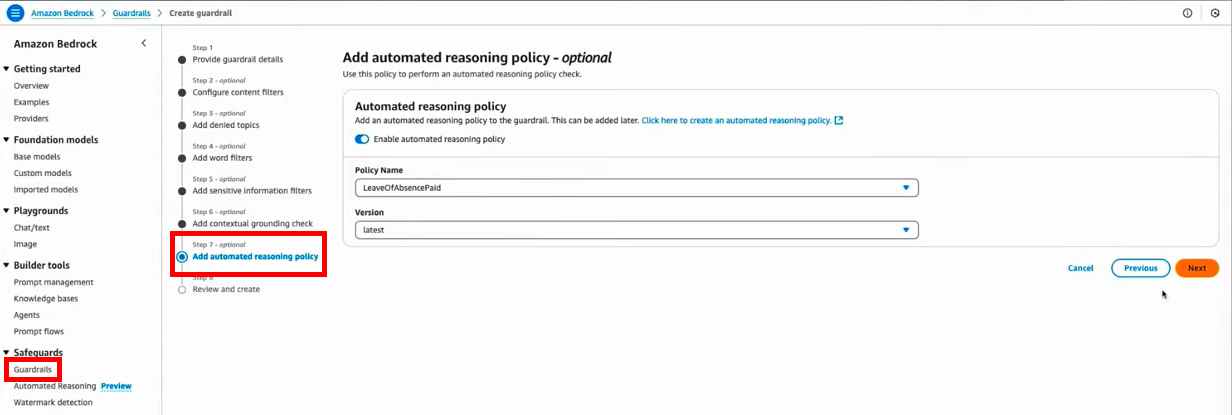
図13 Amazon Bedrock Guardrailsの作成にて「Automated Reasoning(自動推論)」を有効にしている
Amazon Bedrock Guardrailsの作成が完了したら、これをチャットボットに統合することにより、出力の精度、セキュリティ、コンプライアンスを強化することが可能になります。
まとめ
AWS re:Invent 2024の参加レポートとして、Amazon Bedrock
Guardrailsの自動推論チェックを使用した健全で正確な生成AIアプリケーションの構築プロセスについて紹介しました。
AIの生成した内容が事実に基づいた正確なものであるかを自動で推論してくれるのはとても便利で素晴らしい技術ですし、誤った情報が含まれるリスクを減少させてくれる事は、ユーザーとしても、開発者としても非常に助かる事であると感じました。
ただ、それによってハルシネーションが全て解消されるのかというとそこまでは到達していないと思われますので、生成AIを使うときも作るときも、その点に十分注意しながら、全てを生成AIに任せるのではなく、自分の知識と照らし合わせながら生成AIと協力していく必要があると考えます。