
富士ソフトの技術管理統括部 先端技術支援部に所属する清水です。私が所属するロボットインテグレーション室では、ロボットのシミュレーターや開発フレームワークの調査・研究などを実施しています。前編で説明したとおり、LLMをアームロボット制御で活用すると、製造現場のさまざまなニーズに対応できるようになります。より柔軟なロボット制御を実現するために、注目していたのがオープンソースのVLA(Vision-Language-Action)モデル「Open-VLA」です。Open-VLAは97万件ものロボット制御のデータを学習できるため、今後の実用化に向けて大きな期待が寄せられています。
今回は、ロボットインテグレーション室で調査した「Open-VLA」の特徴や可能性、実施中の検証内容、LLMによるロボット制御の将来性を詳しく解説します。

ロボットインテグレーション室での調査工程
ロボットインテグレーション室では、以下の流れで調査を実施しています。
①ソリューション、先行技術調査…現場や市場で発生している課題や注目されている技術について調査
②ライブラリ調査…問題解決に適したパッケージを調査し、対象ライブラリを決定
③研究・検証…選定したパッケージが期待通りに機能するか検証
④研究成果のまとめ・発表…調査結果を資料としてまとめる。社内・外向けサイトに研究事例として掲載
ロボット制御調査の実例
当室が実施しているLLMを用いたロボット制御調査の内容を詳しく紹介します。
①ソリューション、先行技術調査
今回紹介する調査の最終的な目的は“実機アームロボットを用いて、従来の手法とLLMを活用した手法の工数を比較”することです。
調査の実施背景は、社内にて生成AIを用いたロボット制御の話が浮上したこと、お客様にとってもコストと工数を抑えるメリットが大きいことなどが挙げられます。ロボットにLLMを搭載すると、お客様は自然言語でロボットを簡単に操作でき、現場でのロボット導入を促進しやすくなります。ロボット導入による業務効率化や生産性向上なども期待できるでしょう。
②ライブラリ調査
今回の調査は、LLMでロボットを制御できるモデルを対象としました。実際に調査したところ、高い精度・独自性を持ったモデルを複数発見しましたが、調査を進めると研究発表のみでコードが非公開だったり、ライブラリが古くて動作しなかったり、実機での性能が不明瞭なモデルがあったり、多くのモデルで何かしらの課題が見られました。
そのような状況下で私たちは「Open-VLA」と呼ばれるモデルを選定しました。「Open-VLA」は、スタンフォード大学やトヨタ研究所、Google DeepMindなどの研究機関が開発したオープンソースのVLAモデルです。「Open-VLA」を選定した主な理由は、オープンソースで一般の方が利用できるようにドキュメントやツールが整備されていること、利用者が多くて継続的なフィードバックによる品質改善が見込まれるため将来性が期待できることなどが挙げられます。
「Open-VLA」は、画像や命令文を入力し、入力した情報に基づいてロボットの動きを出力できます。97万件ものロボット制御のデータセットを学習させ、ファインチューニングを通じて汎用性を高めているのが特徴です。
③研究・検証
続いて、モデルが適切に動作するかを確認するために、「Open-VLA」で以下の検証を実施しました。
- 学習に必要なロボットの動作データを収集・作成する
- 収集した学習データを用いて「Open-VLA」での学習を実行する
- 学習モデルを使用した推論を通じてロボットの制御を確認する
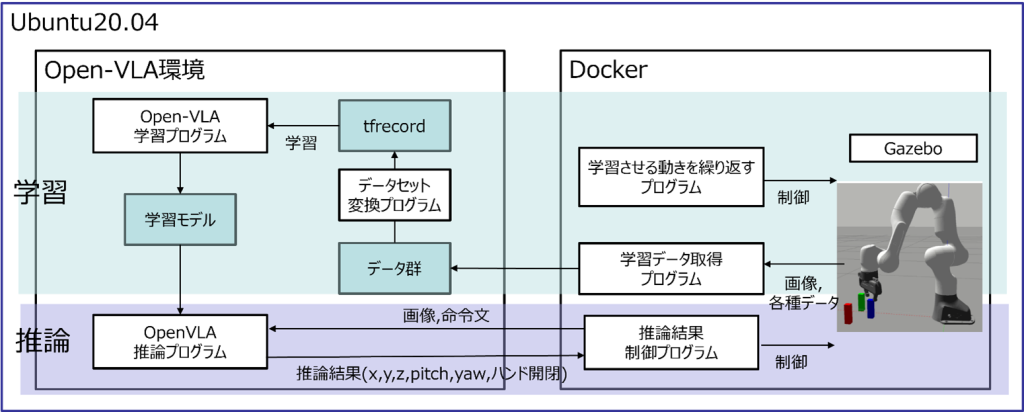
まずは、ファインチューニング用の学習データを収集するために、シミュレーション環境を用意しました。使用したシミュレーターは、アームロボット「Panda」のGazeboサンプルです。今回は、ロボットが青い直方体(ボックス)を把持するというシンプルな動作を繰り返し検証しました。この検証で取得したデータは、アームと対象物体が映っている画像、アームロボットのハンド部分の座標情報などです。
続いて、「Open-VLA」の学習形式へ変換しました。ここでは「rlds_dataset_builder」ライブラリを使用し、ディレクトリに保存されているデータセットをnpy形式(episode0.npy)に変換しました。その後、npy形式をtfrecord形式に変換しました。
※生成に使用した「rlds_dataset_builder」はnpy形式に変換する前処理があり、その後tfrecord形式に変換されます。
次の学習プロセスでは、推奨されているパラメータを用いてロボットが動作した際のエピソードデータ(ロボットのハンドや対象物が映っているカメラ画像、エンドエフェクタの位置に関するデータ、次ステップとの姿勢の差を記録したデータなど)を50個用意し、1万回の学習を実施しました。これにより、「Open-VLA」でのファインチューニングを実施できました。
最後の推論プロセスでは、前ステップの学習プロセスで得た学習モデルを活用しました。シミュレーション環境から取得した「ロボットが認識した画像」と「それに紐付く命令文」を入力し、学習モデルがこれらを解析してロボットが次の動作で必要な座標を計算します。出力した座標をもとにロボットが指定された位置に動作する流れです。このプロセスを経て、ロボットに対する指示をリアルタイムで生成できるようになりました。
④研究成果のまとめ・発表
今後は、「Open-VLA」の学習方法を社内向けの共有資料として全社へ共有したり、COBOTTA実機を用いたピッキングを実施したりといった取り組みを進める予定です。また、従来の手法とLLMを活用した手法の工数を比較し、どの程度の差があるのかも確認しなければなりません。今回の研究結果について、より具体的な成果が出た場合に、詳細にまとめて研究事例として公開できたらと考えています。すでに「Open-VLA」と同じようなLLMを用いたロボット制御ライブラリ「RAI」を用いたCOBOTTAでの制御研究事例を当社サイトにて公開しているので、興味がある方はぜひご覧ください。
AIエージェントフレームワーク「RAI」によるロボット実機制御検証
LLMによるロボット制御の課題・今後の展望
LLMを実行するには、GPUなどの高価なハードウェアが欠かせません。特にリアルタイムでの制御を実現するにはローカルで高性能な計算環境を整備する必要があるので、導入コストが高額になりやすい点が大きな課題といえます。
また、LLMにはハルシネーション(幻覚現象)のリスクがあり、必ずしも正確な出力をするわけではありません。LLMを用いた制御システムは、従来の制御システムと比較して精度や信頼性の部分の不足が課題とされています。
LLMには多くの課題がありますが、今後の展望については大きな期待が寄せられています。たとえば、企業が提供するロボットにLLMを搭載すれば、自然言語による直感的な操作が可能になります。実際に国際ロボット展iREX2023では、音声入力からCOBOTTA用のプログラムを自動生成する技術が紹介されました。
また、VLMの画像認識精度が今後向上すれば、ロボットの環境理解能力が高まり、状況に応じた柔軟な制御が可能になると期待されています。今後は、LLMエージェントを活用したロボット制御にも注目が集まるでしょう。
最後に
LLMはさまざまな分野で活用が進んでおり、ロボット分野においても技術者の負担軽減や、生産性の向上などの効果が期待されています。当室では、LLMを活用したロボット制御の一環として「Open-VLA」に関する調査を進めています。
LLMによるロボット制御には、ハルシネーションの発生や認識精度に関する課題がある一方で、これらの課題を克服するための研究・開発も進められています。市販ロボットへのLLM搭載やLLMエージェントの活用などの取り組みを通じて、高精度かつ安全な制御の実現に向けた技術革新が期待されています。ロボットに関するご相談がございましたら、ロボットインテグレーション室までお気軽にお問い合わせください。
前の記事
LLMによるロボット制御〈前編〉|【現状と課題】アームロボット×LLMで生産性向上を実現する方法とは?



