

はじめに
IaC推進活動大好き!AWS CloudFormation大好き!な“アプリとインフラの気持ちが分かるエンジニア”の大槻です。
アプリケーションの目線から考えると、プログラムのソースコードを管理すると良いことがあります。
- インフラをコードとしてGitで管理できる
- 環境開発の差異をDiffして世代管理できる
- 作成したリソースを独立した単位で構成できる
しかし、IaC(Infrastructure as Code)を推進するには難しいこともあります。
- 脱パラメータシート
- IAMやCW監視の管理を見直す
- レイヤーごとにリソースを管理する
本コラムでは、そのようなIaCに関するインフラエンジニアの悩みを解決するナレッジを紹介します。

テンプレートをレイヤーとして設計する
AWS CloudFormationでは、テンプレートごとにスタックを定義できます。このスタックは分類で分けて管理すると便利です。
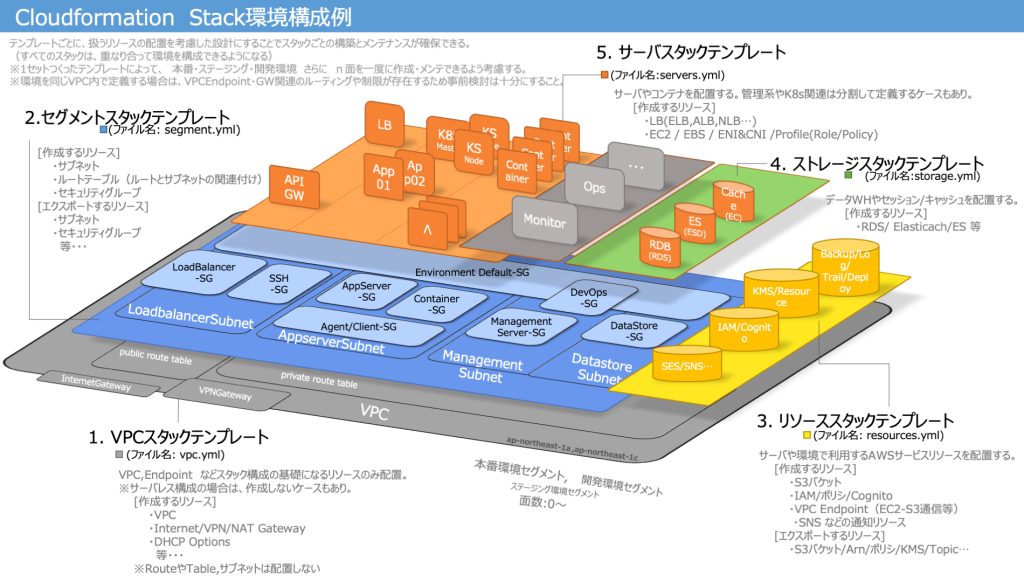
例えば、下図の1. VPCスタックテンプレートから5. ストレージスタックテンプレートまでがレイヤーとして重なっているように、下のレイヤーから上のレイヤーを参照できるような形で定義すると、AWS CloudFormationのインポート・エクスポート機能を使用して依存性や実装が管理できます。
おすすめのレイヤー設計
レイヤー1: VPCスタック
主にVPC、AWS Internet GatewayやドメインのZoneなどを定義します。
ここはあまり欲張らずにEndpointやPeeringを抜いて考えるとよいです。かわりにOutputsセクションで、VPC IDやARNなどをExportしておきます。
レイヤー2: セグメントスタック
レイヤー1 に定義するSubnet、Route、Routetable やコネクションを定義します。
大体の要件が決まりそうであれば、セキュリティグループ自体もここに定義します。
レイヤー3: リソーススタック
AWS Key Management Service、 AWS IAM やAmazon SNS、 Amazon S3など後続から参照しそうなものを定義します。
※監視に使用するAmazon SNSやAmazon EventBridgeは、システムと独立している方がよいと思うので、レイヤー6以降で定義しています。
レイヤー4:データストア、ストレージスタック
Amazon RDSやAmazon ElastiCacheなどを定義します。
メンバーと意見が分かれることもありますが、アプリケーションが参照するSGを記載するために先に定義しておくと書きやすくなります。
DB とAmazon EFSなどのファイルのようなものを分けるのもよいと思います。
Amazon RDSのいるスタックは構築のインスタンスタイプや導入に1時間程度かかってしまうことがあります。なるべくここはAmazon RDSに関連のあるSubnetGroupやOptionGroup程度に留めておいて、レイヤー5以降から参照依存度を低くしておくことがおすすめです。
レイヤー5: サーバースタック
Application Load Balancer、Amazon ECS、AWS Lambdaなどを定義します。
もしAmazon ECSやAmazon ECR、Amazon EKSなどのELBと独立しCI/CD的なデプロイを考える場合は
5.1 ~ 5.5程度に分けて、前者は不動のもの(Amazon ECRやAmazon EKS)、後者にワーカーノードやAmazon ECS((AWS Fargate))などを定義すると、後々破棄して繋げ直しやすくなります。
その他
レイヤー6:
AWS WAF、レイヤー7: endpoint、 レイヤー8: バッチ、9: 監視、10: AIと分けて設計しておくと意外に便利です。あまり依存しないように後方参照にさせることがミソです。
スタックの名称にこだわる
各テンプレートの中を細分化して設計します。
スタックの名称は、プロジェクトのシステム名と環境ステージを付与しておくと管理が楽になります。
Parameterで引数を取ろうとせず、CreateStack時にテンプレートを開いてコピペするのがおすすめです。
Stack名の設定
StackName: CFSystem-d1-server
※CFSystemというプロジェクトのための、開発環境の1面でスタック作成する場合の例テンプレートのヘッダーに以下のように記載しておくとCF作成時にコピペでスタック名を入力できるので便利です。
スタック作成時にコピペし、さらにParameterの指定も記載しておくと忘れにくいです。
CloudformationTemplate.ymlのヘッダー部分
###############################################################################
## AWSTemplateFormatVersionセクション
## 説明: AWS Cloudforamtion 仕様に基づき「'2010-09-09'」固定
AWSTemplateFormatVersion: '2010-09-09'
###############################################################################
## CloudformationTemplate (YAML形式)
## サーバースタック用テンプレート
## StackName: (開発環境でスタック作成するスタック名: CFSystem-d-server)
## p: CFSystem-p-appserver
# # EnvType: p
## s: CFSystem-s-appserver
# # EnvType: s
## d: CFSystem-d-appserver
# # EnvType: d
##パラメータは3、4個程度に絞る
何でもパラメータ化したくなるのがアプリケーションのプロパティの考え方ですが、CreateStackごとに、パラメータを全部テキストフィールドに入力するには、大変手間がかかります。
- SystemName (今回割愛)・・・CFSystem (例)
- EnvType・・・ここで p:production、s:staging、d:develop
- Mensu (今回割愛)
EnvTypeは、環境の種別ごとにパラメータシート扱いのMapping(後述)で環境ごとの変化を分けることができます。
Mensuは、現場でありがちな同じ環境を横展開させたいときに使用します。
ここは欲張らずにMappings対応はしないことが秘訣です。
Mapping を環境の種別ごとに管理する
Mappingをパラメータシートとして考えて、EnvType(環境の種別)を使用して構築に利用します。
- パラメータをEnvType で指定して、起動時に選択できるようにする。
- YAMLで記載するとパラメータシートとしてコメントや仕様を追記できる。
- 完全に脱パラメータシートにならないこともありますが、全てのプロパティを定義して、全てに説明を記載しておくと、記載するときは面倒ですが、後でリリースやパラメータの管理がしやすくなります。
- CFn AWS CloudFormationリソースの持つrequire/non requireに関係なく、全てのパラメータを設定してデフォルト値を記載します。
Mappings セクションの一部抜粋:リソースごとのプロパティを環境種別向けに定義する方法
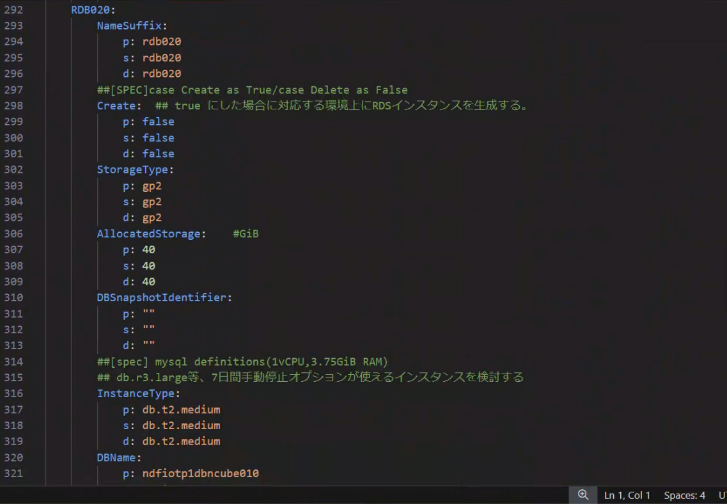
Mappings:
RDB010:
InstanceType:
p: m4.xlarge ## [SPEC] なんでこのインスタンスにしたのかの理由
s: m3.large ## [SPEC] ステージング環境でなんでこのインスタンスにしたのかの説明
d: t3.micro ## [SPEC] どうして開発環境はこのインスタンスタイプでいいかの説明
StorageSize: ## [ストレージサイズや単位を書いておくこと : Gib]
p: 100 ## [SPEC] 10000ユーザー * 10%アクティブ状態 * 1レコード 1MByte * 100行 などフェルミ推定的な数値の根拠も コードないよりもMappingに記載することおすすめです。チューニングや判断がしやすくなります
s: 80
d: 20
Condition を使用してインスタンスの作成要否や環境種別の判定でパラメータを操作する
Mappings の中に“Create : true / false”という値を用意しておきます。
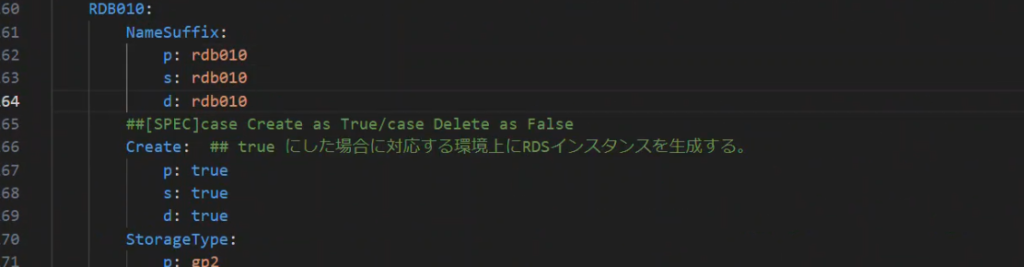
Condition の中でIsCreateRDB010を作る判定を定義します。
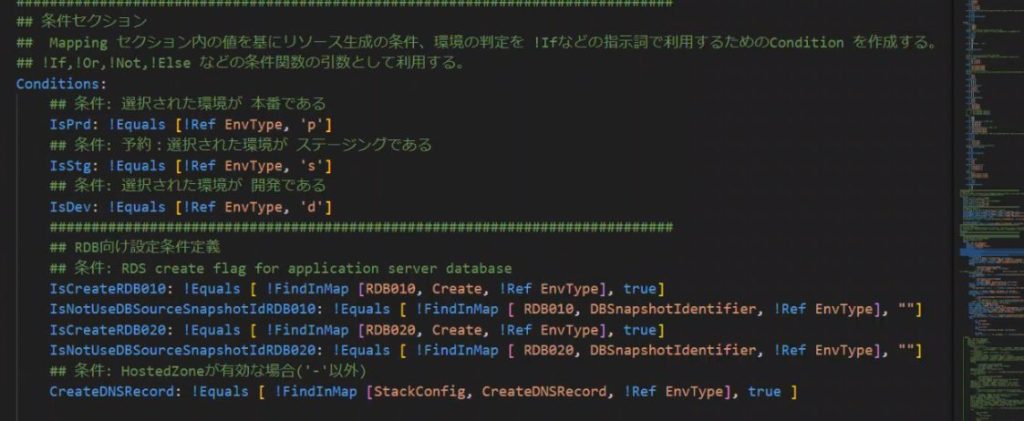
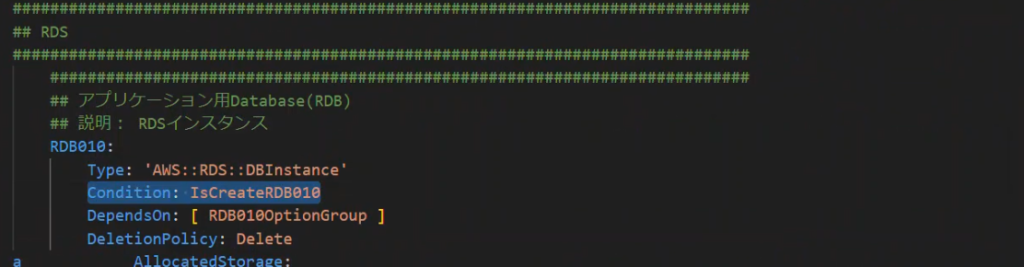
実際のリソース定義の中でConditionを使用することで、Mappings 定義をtrue からfalse に切り替えてスタック更新するだけで、DBの削除や再作成が可能になります。
リソース名は!Joinを使用して命名規則に従う
コードの書き方はいろいろあると思いますが、以下のようにSNipetにしておくと便利です。最近のAWSコンソールでは、リソース時にタグや名称がつけられるようになったので、比較的はやく「どの環境」「どのシステム」「どのリソース」なのか目視しやすくなります。
文字連結機能を使用して、システム名称やIDを生成するTips
!Join [ '', [ !Ref SystemName, '-',!FindInMap [StackConfig,EnvLabel,!Ref EnvType], !Ref Mensu, "-rds-", !FindInMap [ RDB010, NameSuffix, !Ref EnvType ] ] ]連結した文字列の 例
CFSystemName-d1-rds-RDS010<エクスポート>他のスタックから参照しやすくする
作られたリソースは大概ARNを返しますが、リソースのIDや名称を返すものもあるのでValueの値には!Ref( リターンされるARN)のほか!GetAttリソース論理名.addresなどでIPアドレス情報を返す定義をしてテンプレートをエクスポートしておくと、後方のテンプレートから直接値を参照するのに便利です。
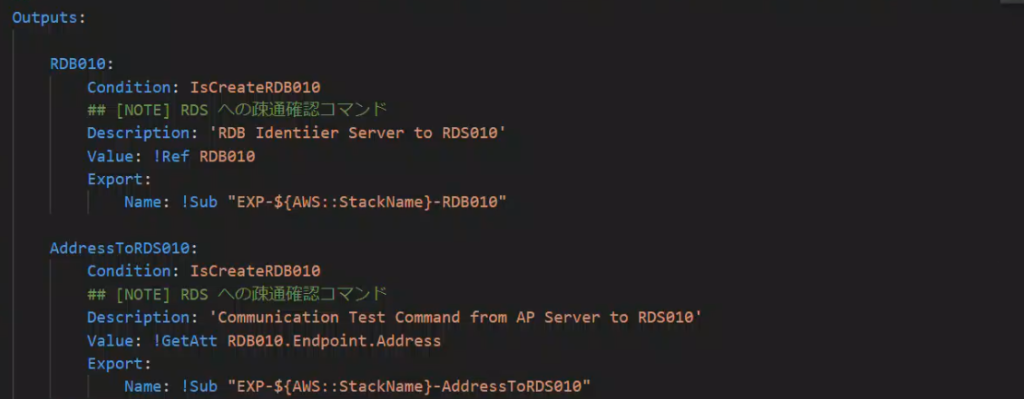
<インポート>前方スタックから参照できることを理解する
エクスポートしたらインポートできるようにしてあげると便利です。
例:リソースのインポートのTipsを見やすくしたもの
"Fn::ImportValue":
!Join [
'',
[
!FindInMap [StackConfig,VPC,ImportPrefixOfVpc], ## → "EXP-CFSystem-"
!FindInMap [StackConfig,EnvLabel,!Ref EnvType],
!Ref Mensu,
"-segment-",
"LoadBalancerSubnet010" ## 素直に論理名を書いておくと参照しやすい
]
]
インデントを入れて見やすくしておきます。
例:リソースのインポートのTips
###[NOTE] Subnetsを指定して セグメントスタックでエクスポートしたロードバランサ作用のサブネットA-Z をインポートする例
Subnets:
##internet-facing --> [PublicSubnet1,PublicSubnet2]
- "Fn::ImportValue": !Join [ '', [ !FindInMap [StackConfig,VPC,ImportPrefixOfVpc], !FindInMap [StackConfig,EnvLabel,!Ref EnvType], !Ref Mensu, "-segment-", "LoadBalancerSubnet010" ] ]
- "Fn::ImportValue": !Join [ '', [ !FindInMap [StackConfig,VPC,ImportPrefixOfVpc], !FindInMap [StackConfig,EnvLabel,!Ref EnvType], !Ref Mensu, "-segment-", "LoadBalancerSubnet020" ] ]
おまけ: NestedStack は、あまり使用しない
好みもあると思いますし、NestedStackを便利だと思う方もいらっしゃるかもしれません。構成管理をIaCにするときもそうですが、初期導入時にAmazon S3にスタックを入れて、入れ子にしたものを一気に作るため、準備が必要で手間がかかります。
そこで最近提供されたのが、AWS CloudFormation Git同期の機能です。
テンプレートをGitと連携すると更新を行う機能です。便利な反面、更新するタイミングについては戦略を立てる必要があると思います。この話はまた別のコラムでご紹介します。
AWS CloudFormation Git 同期を使った作業:
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/git-sync.html
まとめ
いくつかのTipsをご紹介しました。
AWS CloudFormationは、「やってみると楽しい」、「奥が深い」、「シンプルに書ける」のではないでしょうか。「冗長だからAWS CDKだよ!」という考えもあるかもしれません。
ちょっとした要求をこなしたい場合には、AWS CDKではレイヤー1、2あたりを考慮した記載が必要になるなどのお作法があります。あまりにお作法に踊らされているなと思ったら、AWS CloudFormationを使ってみてはいかがでしょうか?
筆者は実際にこのTipsを使って、数万行のコードでIaC構成を書いてきました。ぜひお試しを!
富士ソフトのAWS関連サービスについて、詳しくはこちら



