

IoTクラウド基盤アーキテクトの森⽥です。お客様のIoTサービスを実現するAWSアーキテクチャの検討、提案、構築を行っています。最近はIoTへの生成AI活用にも幅を広げて技術検証を行っています。
AWSの生成AIサービスであるAmazon Bedrockは様々な基盤モデルをAPIで簡単に利用できるサービスです。単に基盤モデルを呼び出せるだけではなく、生成AIアプリケーションを開発する際に必要な機能がたくさん提供されています。
- Knowledge Bases for Amazon Bedrock:ナレッジベース機能
- Agents for Amazon Bedrock:エージェント機能
- Guardrails for Amazon Bedrock:自社ポリシーに沿ったセーフガード適用機能
- Model evaluation:生成AIモデルの評価機能
- Watermark detection:生成画像の透かし機能
ナレッジベース機能を提供するKnowledge Bases for Amazon Bedrockが、3月1日(金)にハイブリッド検索(セマンティック検索とテキスト検索)のサポートを開始しました。
ハイブリッド検索機能の動作検証と合わせて、日本語環境での精度向上について技術検証しました。

Knowledge Bases for Amazon Bedrockとは
Knowledge Bases for Amazon BedrockはAmazon Bedrockの機能の一つで、生成AIのユースケースとして広く使用されるRAG(Retrieval-Augmented Generation:検索拡張生成)に必要なナレッジベースを簡単に実現できる機能です。
通常、RAGを構成する場合は、質問文のベクトル化や検索、回答生成と複数のステップを踏む必要があります。
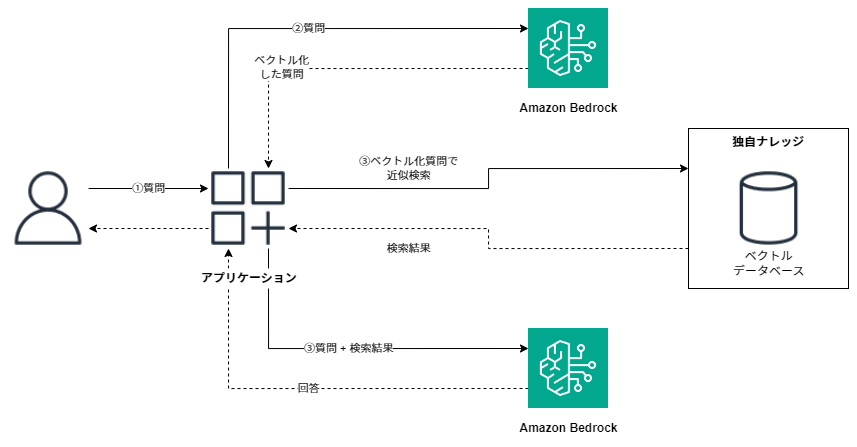
Knowledge Bases for Amazon Bedrockはこういった複数のステップを内部で実施する仕組みになっており、Amazon Bedrockの利用者はAPIを一つ呼び出すだけで回答を受け取ることが可能です。また、ウィザードに従うだけで独自ナレッジを蓄積するためのAmazon OpenSearch Serverlessを作成できます。
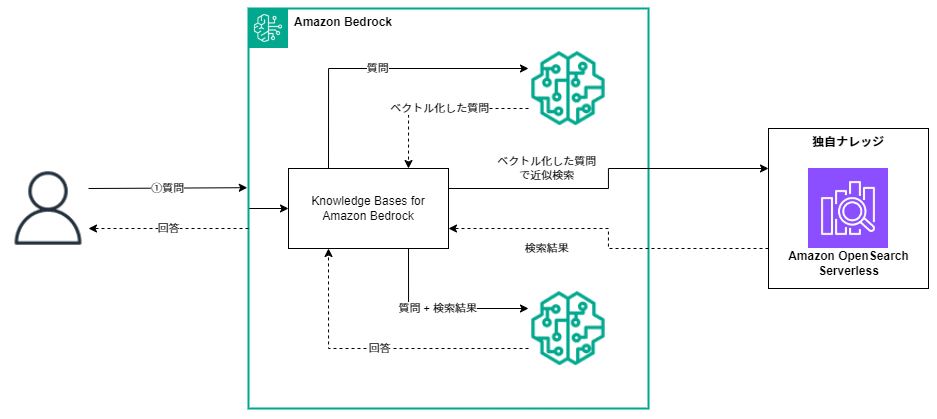
Knowledge Bases for Amazon Bedrockを使用するとRAGアプリケーションを迅速に構築できます。
Knowledge Bases for Amazon Bedrockの構築手順
Knowledge Bases for Amazon Bedrockの構築手順を解説します。
独自ナレッジとして登録するデータは、Amazon S3に格納する必要があります。Amazon S3バケットは事前に作成しておいてください。
1.Amazon Bedrockの管理画面にアクセスします。
左メニューの「[ナレッジベース]をクリックします。
2.[ナレッジベースを作成]をクリックします。
3.ナレッジベース名を入力し、[次へ]をクリックします。
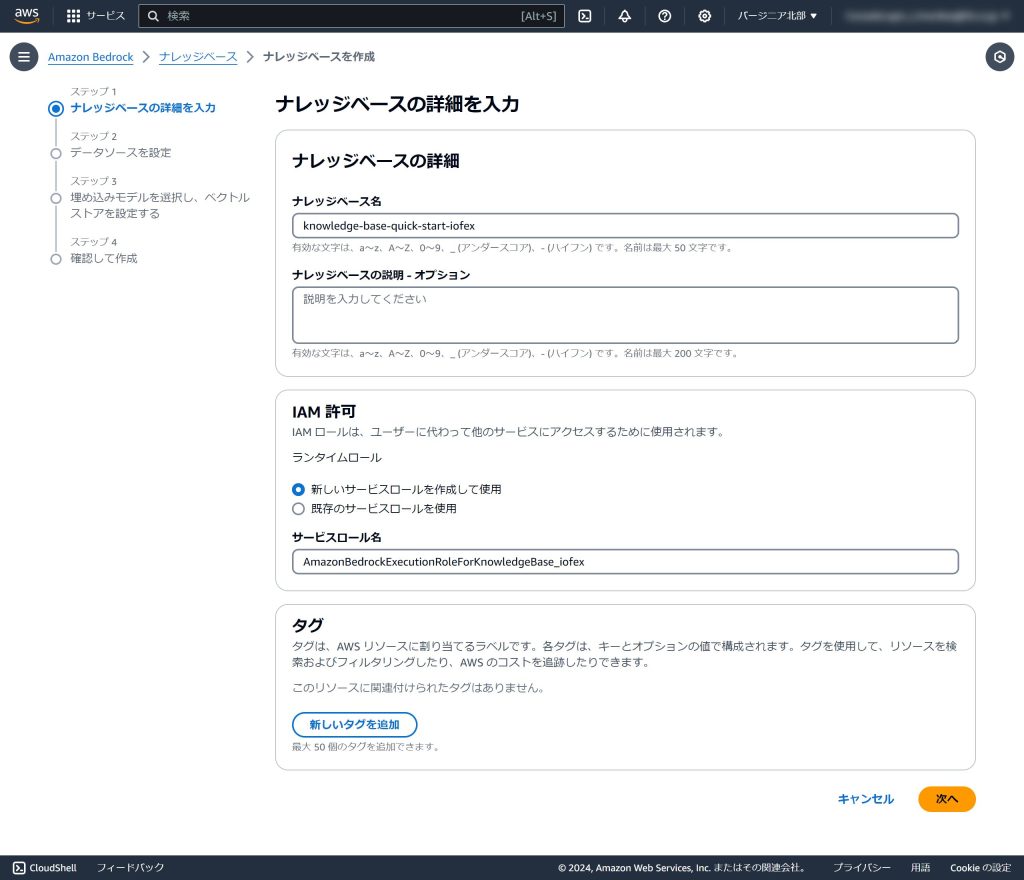
4.データソース名とS3 URIを入力し、[次へ]をクリックします。
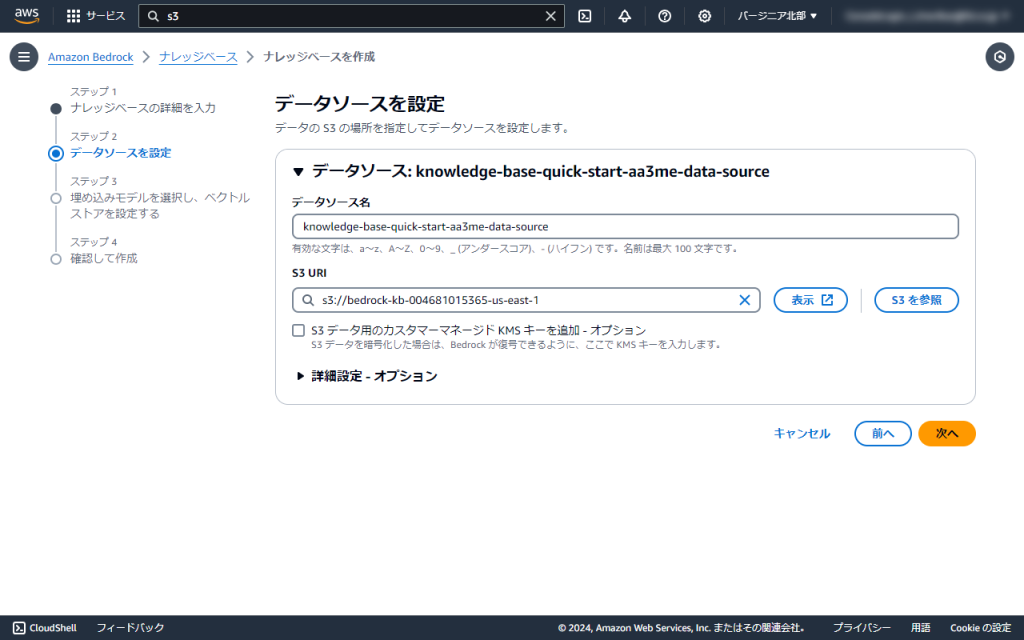
5.埋め込みモデルは[Titan Embeddings G1 - Text]を選択、ベクトルデータベースは[新しいベクトルストアをクイック作成]を選択します。「次へ」をクリックします。
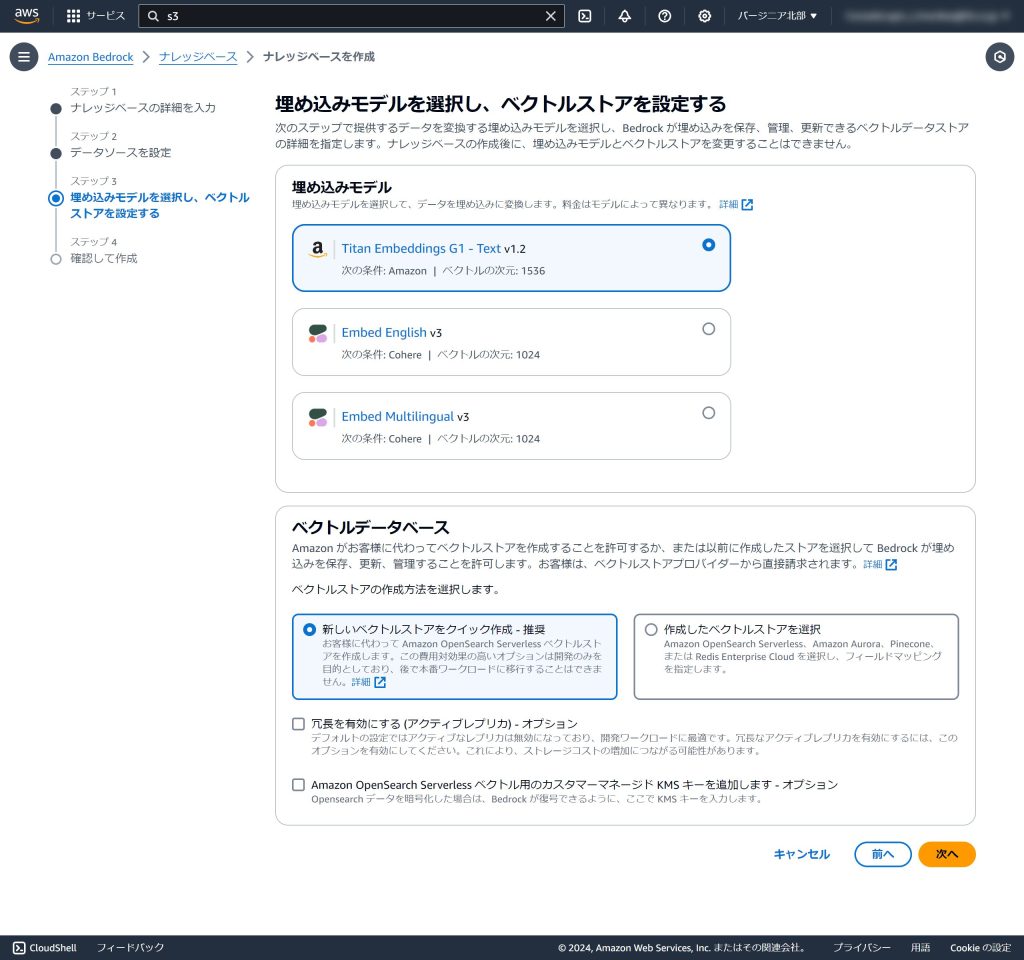
6.確認画面が表示されますので、内容を確認後[ナレッジベースを作成]ボタンをクリックします。(Amazon OpenSearch Serverlessが作成されますのでこの画面で5~10分程度時間がかかります。)
7.ナレッジベースが作成されました。
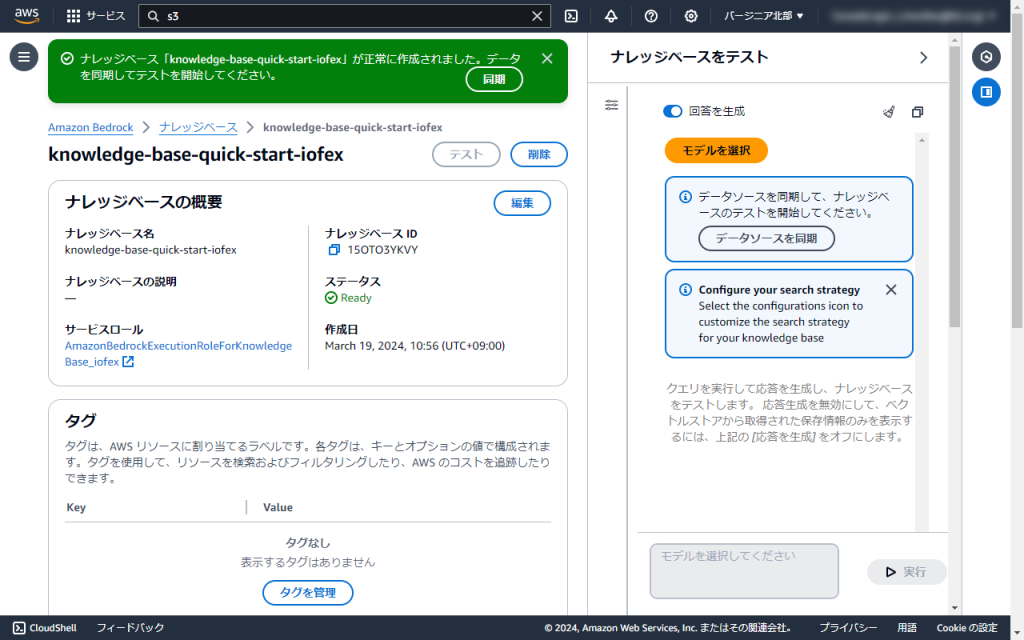
検証のため、DX白書2023のPDFをAmazon S3に格納し、同期しました。
https://www.ipa.go.jp/publish/wp-dx/dx-2023.html
クイック作成で作成した状態での日本語性能の確認
クイック作成で作成したAmazon OpenSearch Serverlessのインデックスは以下の定義となっています。
| マッピングフィールド | データタイプ |
|---|---|
| id | text |
| AMAZON_BEDROCK_TEXT_CHUNK text | text |
| AMAZON_BEDROCK_METADATA | text |
| bedrock-knowledge-base-default-vector knn_vector | knn_vector |
Amazon OpenSearch Serverlessではアナライザーとしてインデックス登録時の一連の処理を登録できますが、クイック作成で作成したインデックスはアナライザーが未指定でした。
アナライザーでは通常以下の処理を行います。
| No. | 処理名 | 処理の内容 | 具体例 |
|---|---|---|---|
| 1 | Character Filter(オプション) | テキスト内の文字の置換、削除 | 半角カナ->全角カナ変換 アパート → アパート |
| 2 | Tokenizer(必須) | テキストの分割 | 吾輩 / は / 猫 / である |
| 3 | Token Filter(オプション) | テキスト分割後の後処理 | これ、それ、あれなどの頻出語を除去する |
日本語対応アナライザーの例
| 処理名 | 例 |
|---|---|
| Character Filter | icu_normalizer |
| Tokenizer | kuromoji_tokenizer |
| Token Filter | kuromoji_baseform、ja_stop |
日本語処理の際のアナライザーの解説は以下のAWS Black Belt資料で詳しく説明されていますのでご参照ください。
Amazon OpenSearch Service 機能解説 – 検索編 AWS Black Belt Online Seminar
Knowledge Bases for Amazon Bedrockのテスト実行では、セマンティック検索(ベクトル検索)とハイブリッド検索(ベクトル検索+全文検索)が選択できますが、全文検索のみの検索結果を確認することはできませんでした。そのため、OpenSearch DashboardsのDev Toolsを使用して検索性能を確認します。
例えば「スマートシティ」で検索すると、7件ヒットします。
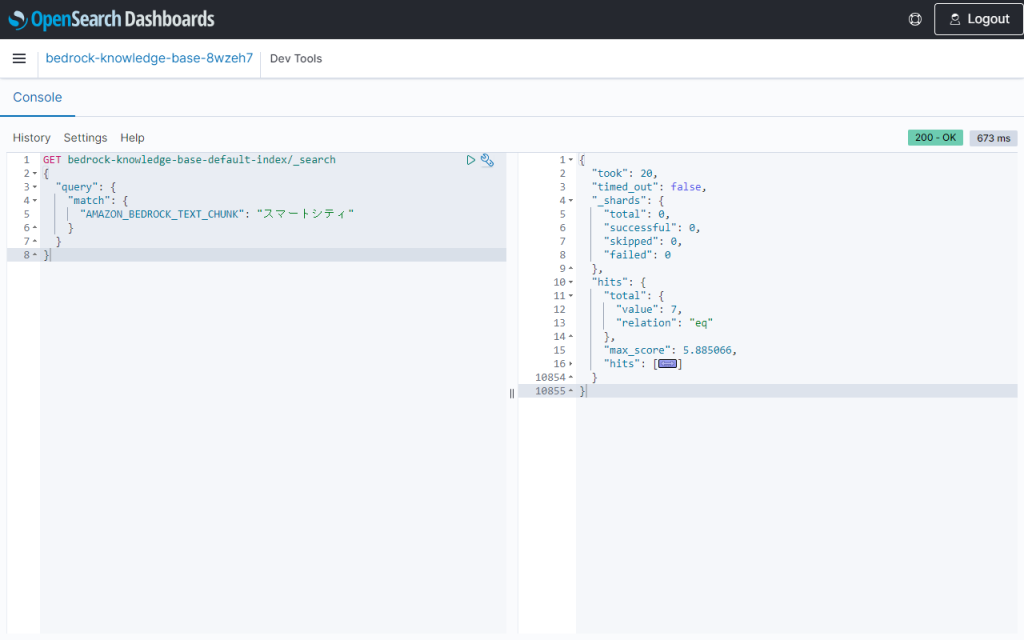
クイック作成で作成したインデックスはアナライザーとしてCharacter Filterが未設定のため、全角文字と半角文字は別の文字として判断されます。インデックス登録した文書には全角の「スマートシティ」しか存在しないため、半角で「スマートシティ」と検索した場合はヒットしません。
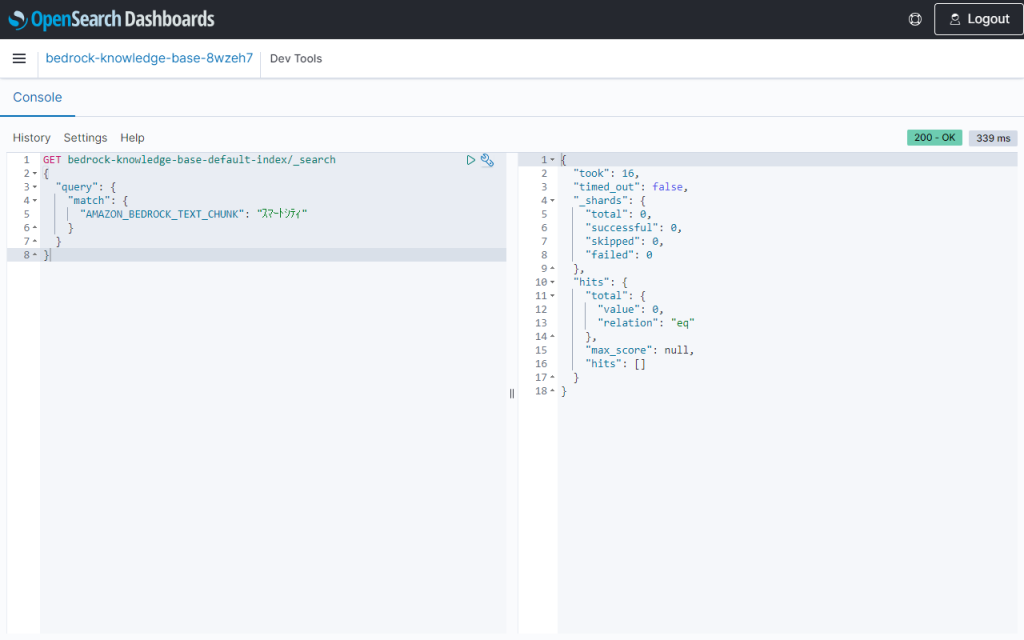
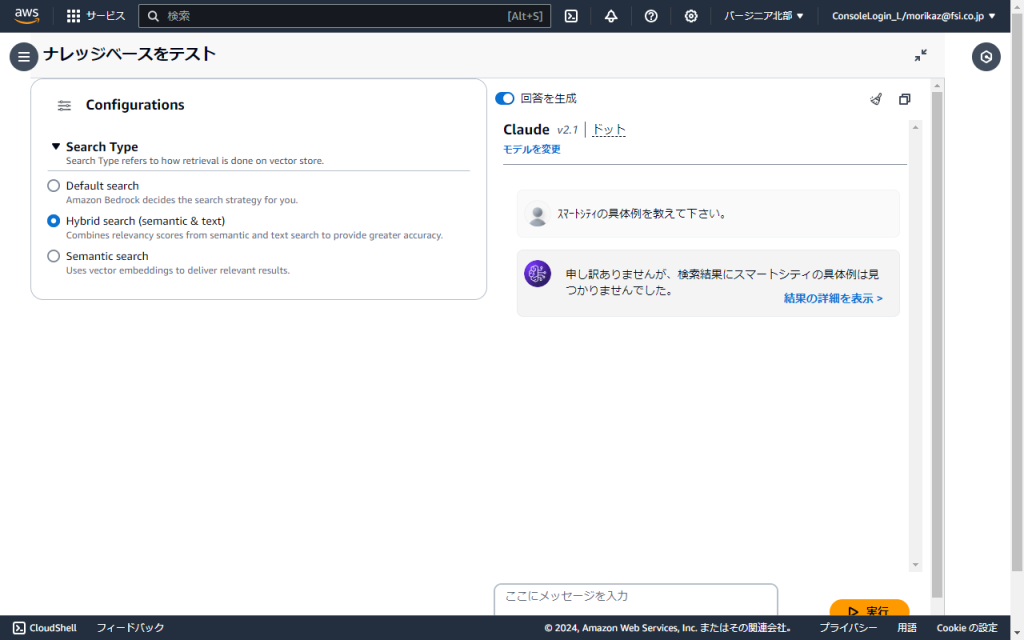
この状態でKnowledge Bases for Amazon Bedrockで「スマートシティの具体例を教えて下さい。」と問い合わせても回答が生成されませんでした。ハイブリッド検索なので、全文検索だけでなくベクトル検索でもうまく取得できていないということが分かりました。
日本語性能改善の設定
それではインデックスに日本語アナライザーを設定して検索精度が改善するか検証します。
クイック作成で作成したインデックスを参考に「bedrock-knowledge-base-japanese-index」という名前の別のインデックスを作成しました。
settingsセクション内でアナライザーを定義(analysis部)し、AMAZON_BEDROCK_TEXT_CHUNKプロパティのアナライザーとして指定します。
| 設定項目 | 設定内容 |
|---|---|
| Character Filter | icu_normalizer |
| Tokenizer | kuromoji_tokenizer |
| Token Filter | kuromoji_baseform、ja_stop |
日本語アナライザーを設定したインデックスの作成(Dev Toolsで実行)
PUT bedrock-knowledge-base-japanese-index
{
"mappings": {
"properties": {
"AMAZON_BEDROCK_METADATA": {
"type": "text",
"index": false
},
"AMAZON_BEDROCK_TEXT_CHUNK": {
"type": "text",
"analyzer": "custom_kuromoji_analyzer"
},
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1536,
"method": {
"engine": "nmslib",
"space_type": "cosinesimil",
"name": "hnsw",
"parameters": {}
}
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"knn.algo_param": {
"ef_search": "512"
},
"knn": "true",
"analysis": {
"analyzer": {
"custom_kuromoji_analyzer": {
"tokenizer": "kuromoji_tokenizer",
"filter": [
"kuromoji_baseform",
"ja_stop"
],
"char_filter": [
"icu_normalizer"
]
}
}
}
}
}
}
このインデックスを参照したナレッジベースを作成します。
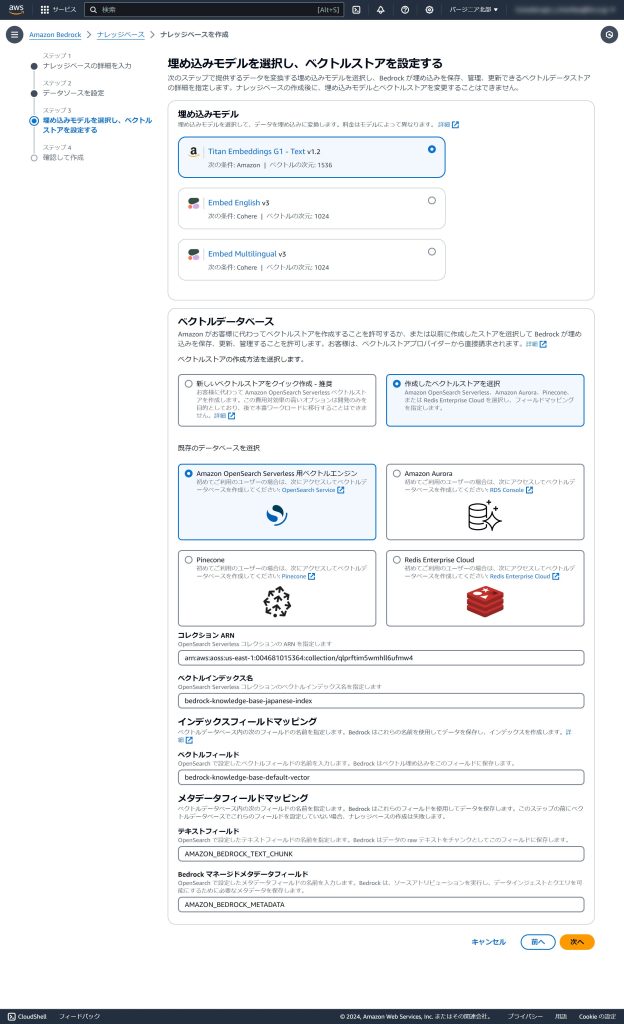
ベクトルデータベースの作成手順で、[作成したベクトルストアを選択]します。
| 項目 | 設定値 |
|---|---|
| コレクション ARN | OpenSerch ServerlessのコレクションARN |
| ベクトルインデックス名 | bedrock-knowledge-base-japanese-index |
| ベクトルフィールド | bedrock-knowledge-base-default-vector |
| テキストフィールド | AMAZON_BEDROCK_TEXT_CHUNK |
| Bedrock マネージドメタデータフィールド | AMAZON_BEDROCK_METADATA |
ナレッジベースが作成できたら、再度同じドキュメントを同期します。
日本語性能改善の検証
日本語アナライザーを追加したインデックスに対して、先ほどと同様の検索を行います。
「スマートシティ」で検索すると40件ヒットしました。
日本語アナライザー未指定のときは7件だったので、ヒット数が増えました。
詳細は不明ですが、誤ったものがヒットしているのではなく、検索キーワードを正しく含んだ結果でした。
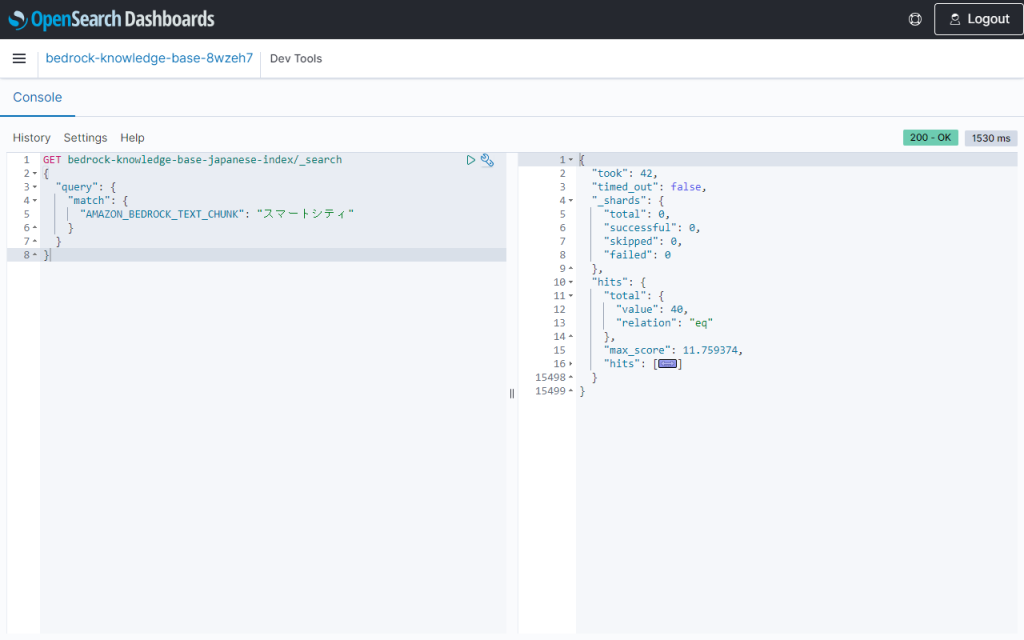
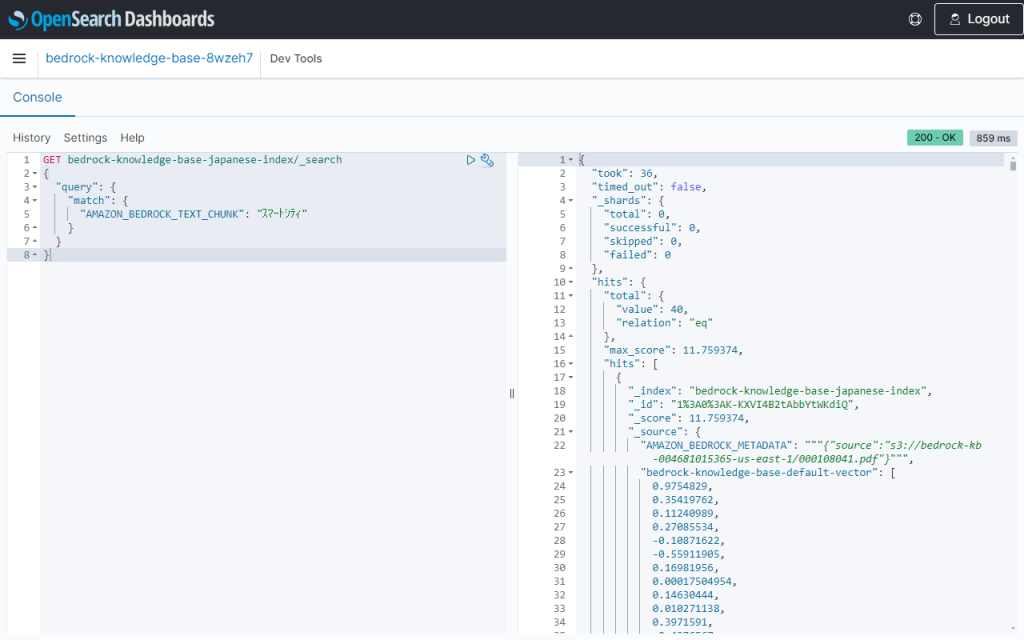
半角の「スマートシティ」でも同じ件数がヒットしました。全角/半角の揺れの補正が正しく行われています。
Knowledge Bases for Amazon Bedrockにおいても、「スマートシティの具体例を教えて下さい。」という問い合わせに対して、回答を生成することができました。
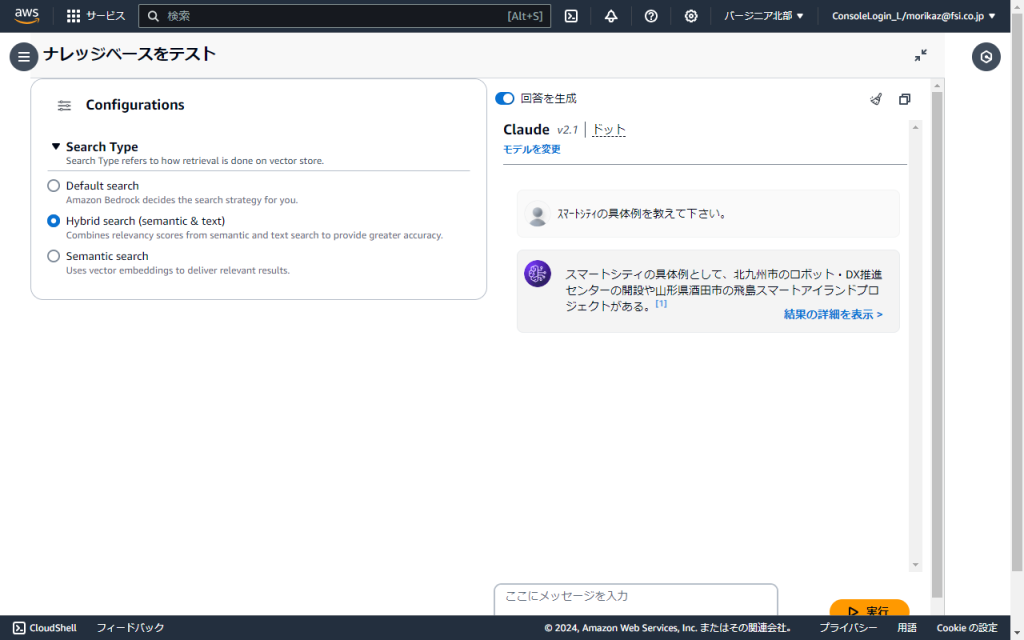
アナライザーを適切に設定することで、Amazon OpenSearch Serverlessの検索精度を向上させることができ、結果としてKnowledge Bases for Amazon BedrockでのRAG品質の向上につなげることができました。
まとめ
生成AIの活用の一つとしてRAG導入が活発に進んでいます。当社が提供しているAmazon Bedrock導入ソリューションは、Amazon BedrockとAmazon Kendraの構成を標準としていますが、お客様に合わせた個別のカスタマイズも可能です。Amazon Kendraの代わりにAmazon OpenSearch Serviceを使用してRAGを導入された事例もあります。データソースの豊富さではAmazon Kendra、細かな検索精度のチューニングではAmazon OpenSearch Serviceといった使い分けなど、当社のノウハウを活かしたご提案が可能です。ぜひ、お問い合わせください。
Amazon Bedrock導入ソリューションについて、詳しくはこちら



