
IoTクラウド基盤アーキテクトの森⽥です。お客様のIoTサービスを実現するAWSアーキテクチャの検討、提案、構築を行っています。
ラスベガスで開催された「AWS re:Invent 2024」に参加してきました。会場の広さも当然ですが、AWSに興味のある人がこんなに集まるのかと、毎年驚かされます。
毎年様々な新サービスの発表がありますが、私が今年最も注目したのは、12月3日(火)のDr. Swami Sivasubramanianのキーノートで発表された「Amazon Bedrockナレッジベースでのstructured data retrieval(構造化データ検索)のサポート」です。

BedrockナレッジベースはノーコードでRAGの仕組みを構築できる機能です。これまではPDFドキュメントなどの非構造化データをサポートしていましたが、今回、構造化データもサポートに追加されました。
生成AIを使って構造化データを検索するには、NL2SQLと呼ばれる「自然言語のSQLへの変換」を行う必要があります。このNL2SQLの機能をAWSが提供してくれることにより、構造化データに対する自然言語での問い合わせが可能になります。
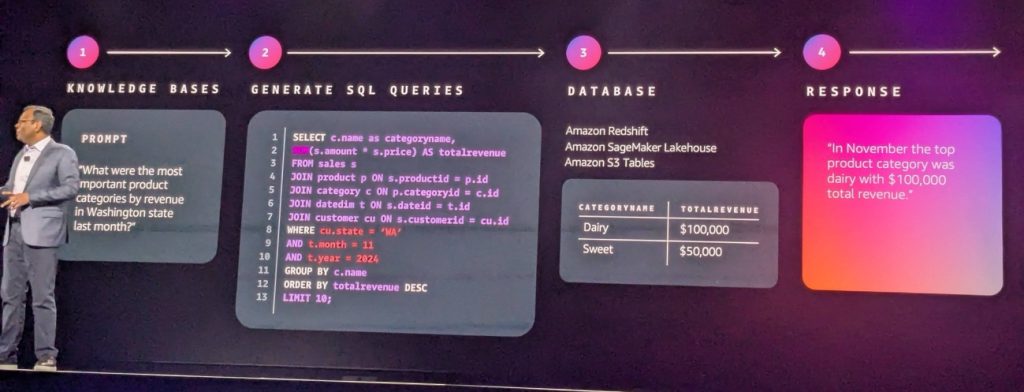
私が以前投稿した「AWS IoT TwinMakerとAmazon Bedrockを組み合わせた設備管理ソリューションの検証」でNL2SQLを実装する方法を解説していますが、この部分がBedrockナレッジベースの機能として提供されることになりました。
早速、AWS IoT SiteWiseのデモデータを使用して検証しました。

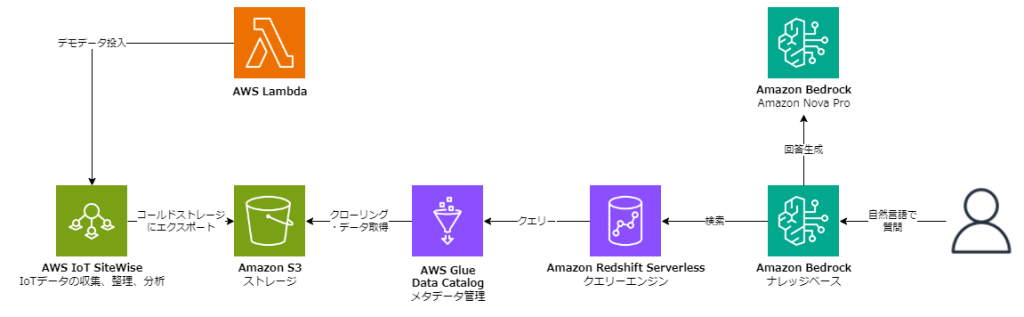
全体構成図
Amazon BedrockとAWS IoT SiteWise以外にも色々なサービスが登場するので複雑に見えますが、実は設定のみで簡単に構築が可能です。
構築手順
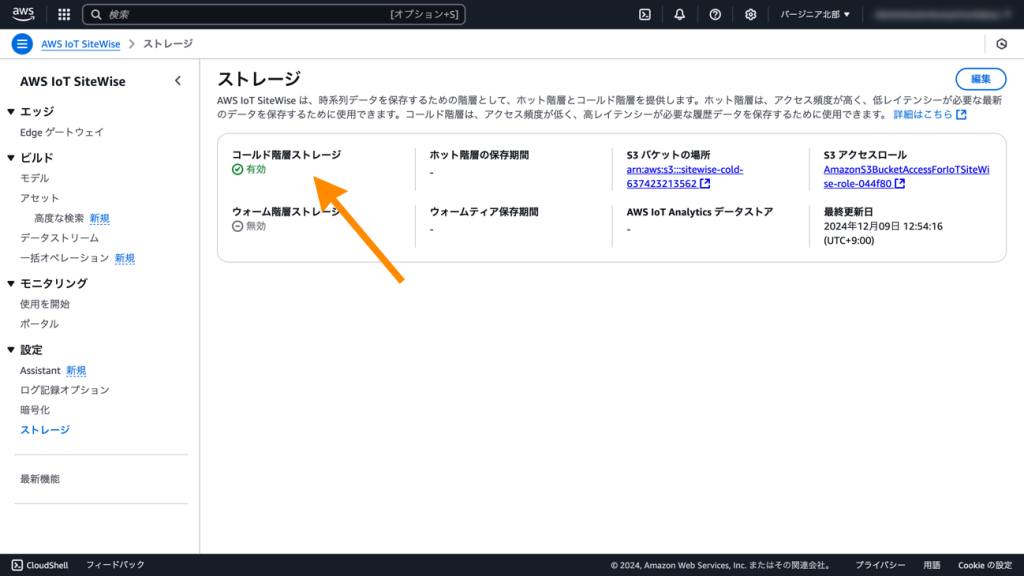
AWS IoT SiteWiseの設定を行いコールドストレージにエクスポートする
AWS IoT SiteWiseの管理画面を開き、[ストレージ]メニューから、[コールド階層ストレージ]を有効化します。
続いてデモデータを投入します。AWS IoT SiteWiseのトップ画面で[デモを作成]をクリックします。
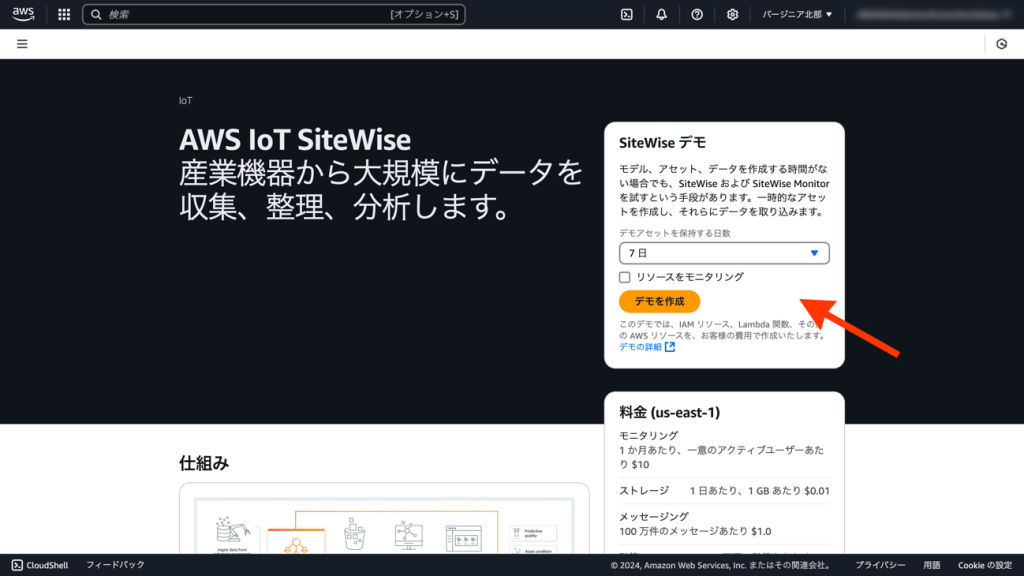
デモデータとして、以下のようなアセットが生成されます。
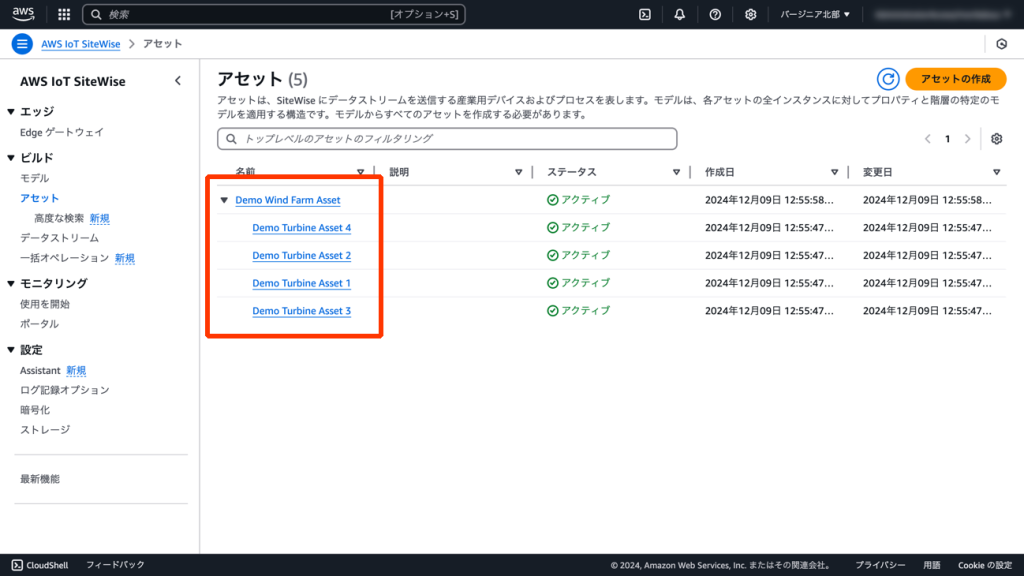
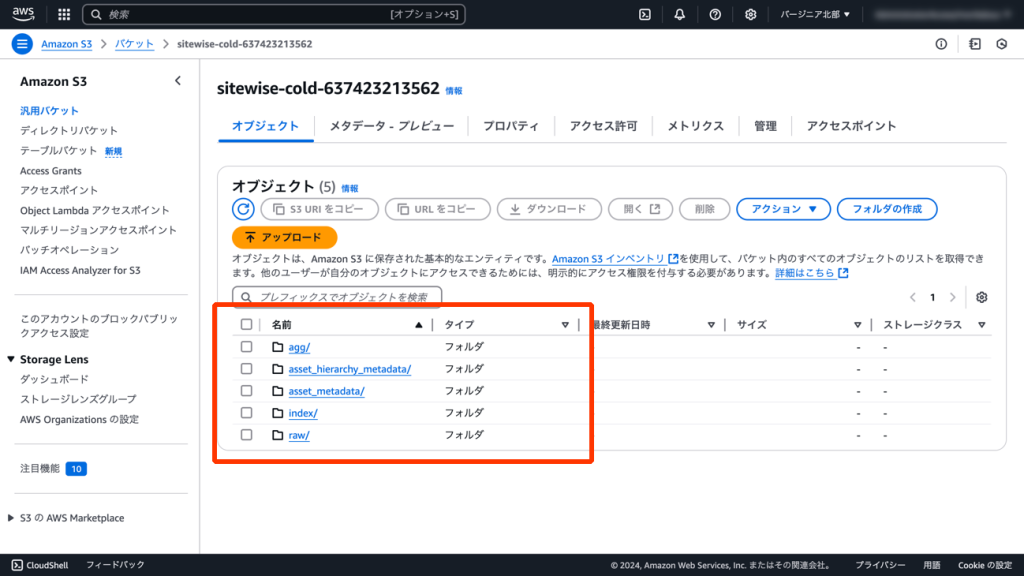
デモデータはコールドストレージの設定により、6時間ごとにAmazon S3にエクスポートされます。
AWS Glueでデモデータのテーブルを作成し、Amazon Redshift Serverlessの使用を開始する
[AWS Glue] - [Data Catalog] - [Crawlers(クローラー)]機能を使い、S3のデータからData Catalogにテーブルを作成します。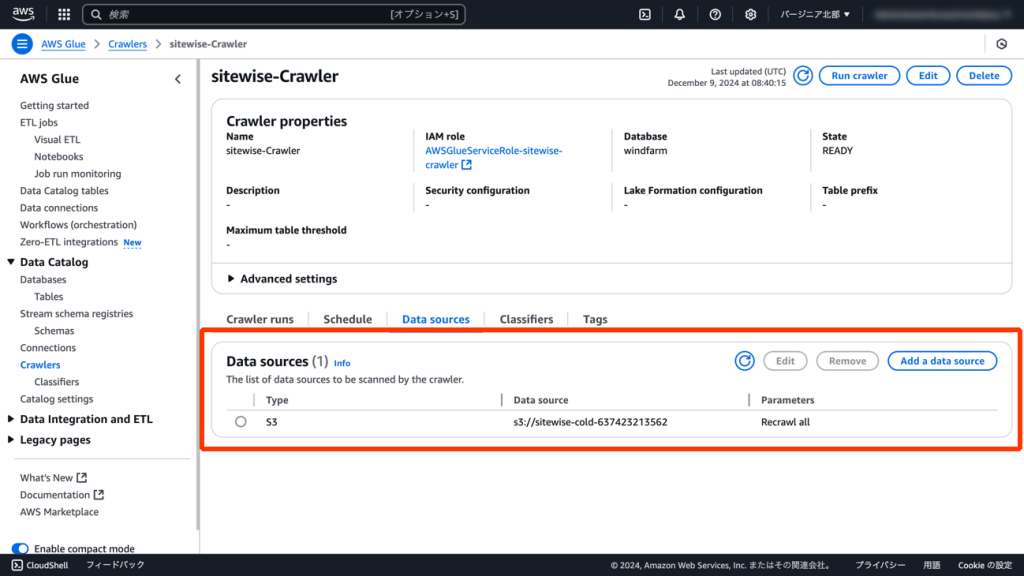
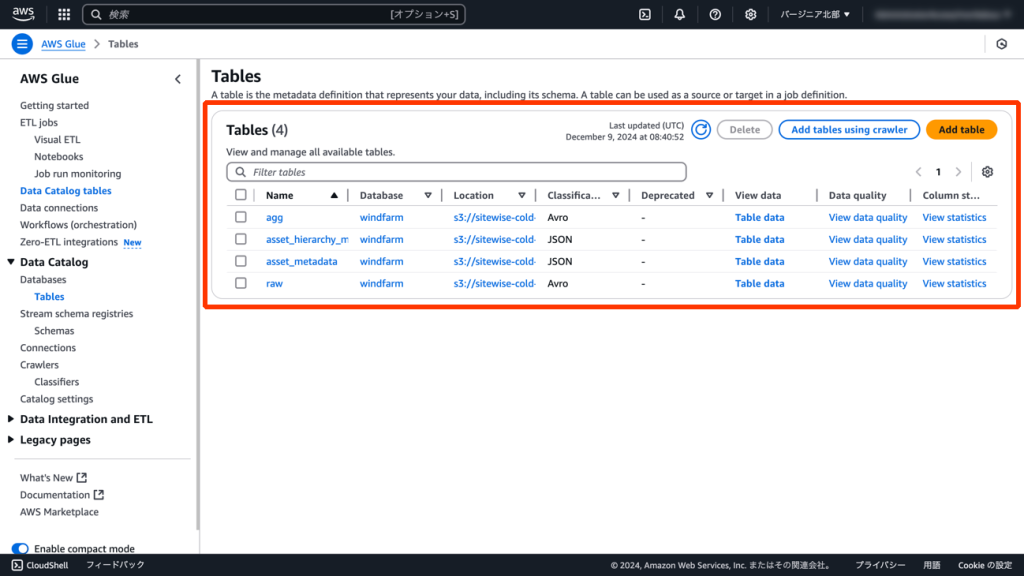
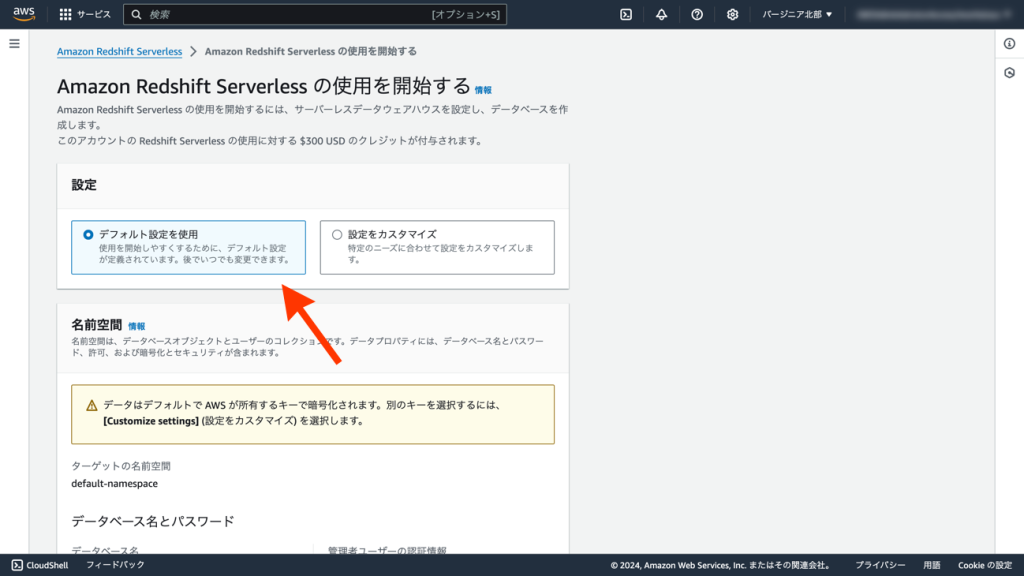
次に[Amazon Redshift Serverlessの使用を開始する]にて[デフォルト設定を使用]を選択します。
Amazon Bedrockでナレッジベースを設定する
[Amazon Bedrock] - [ナレッジベース]にて「Knowledge Base with structured data source」を選択して、ナレッジベースを作成します。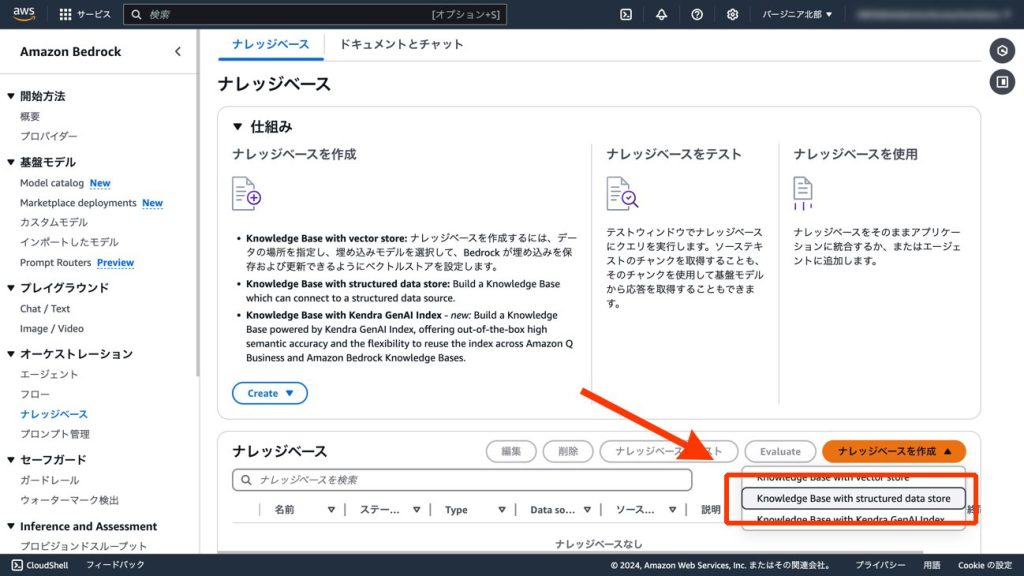
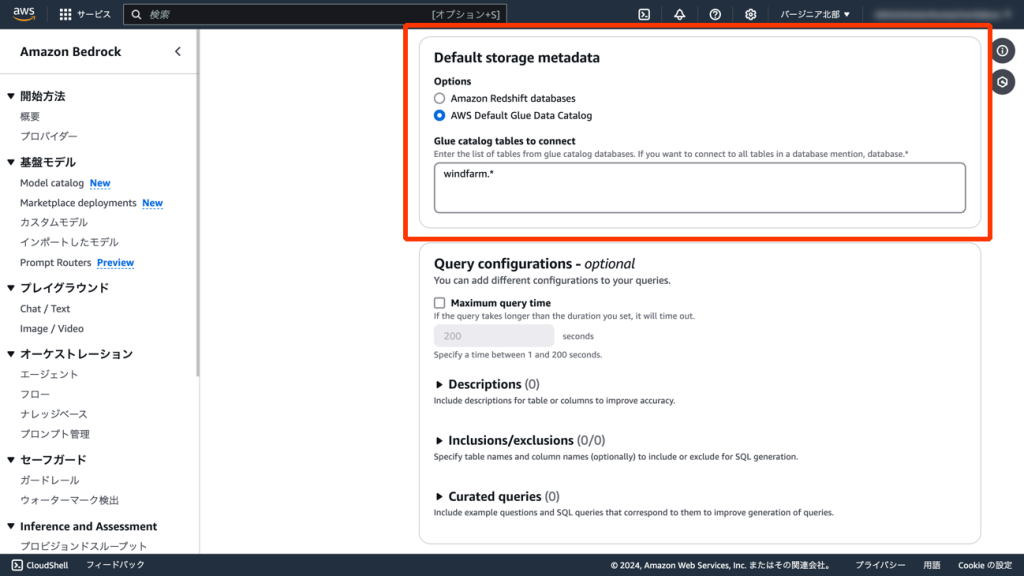
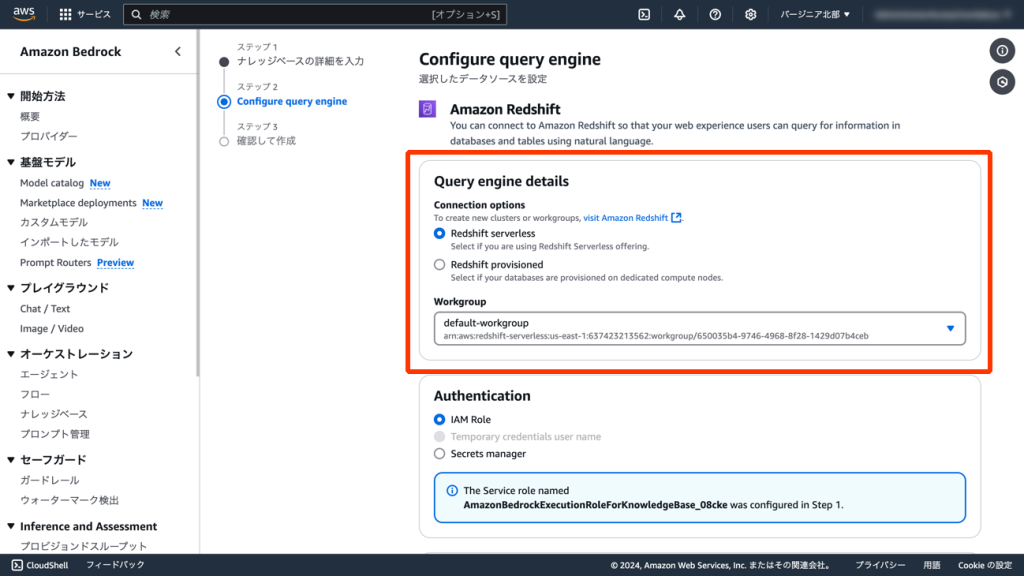
これでAmazon Bedrockナレッジベースの設定は完了です。
他にIAM(AWS Identity and Access Management)やAmazon Redshiftの権限について設定が必要ですが、込み入った手順になるため解説は省略します。そちらについては公式ドキュメントを参照ください。
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-prereq-structured.html
検索を実行
Amazon Bedrockのマネジメントコンソールで[テスト]を押下し、[ナレッジペースでテスト]で検索を試します。
まずは、「アセット名を一覧で取得して」と質問します。すると、「Demo Turbine Asset 4」が複数返却されました。どうも、データの先頭の値を抽出しているようです。
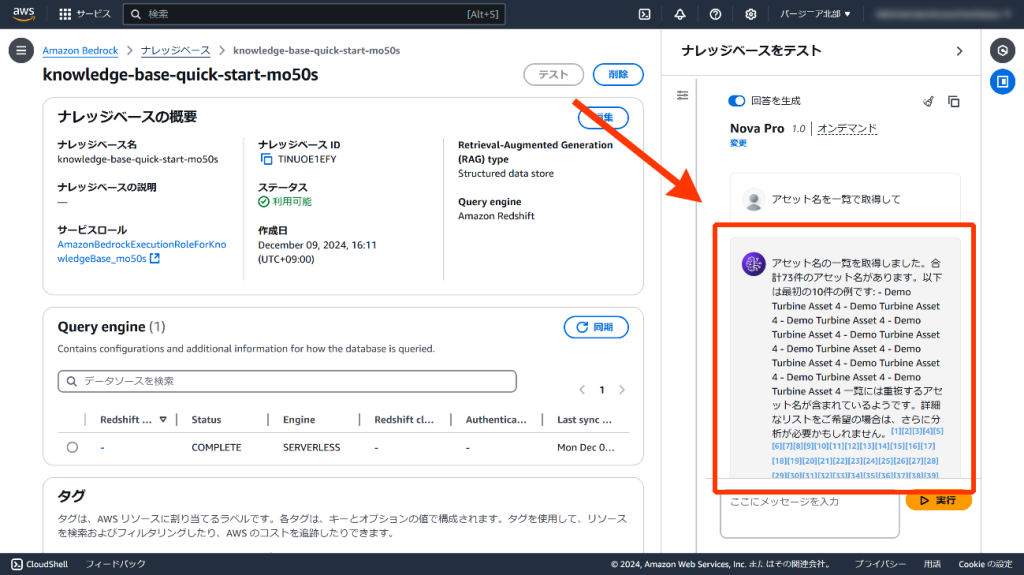
質問を「アセット名の重複を排除して一覧取得」とすると全件取得することができました。
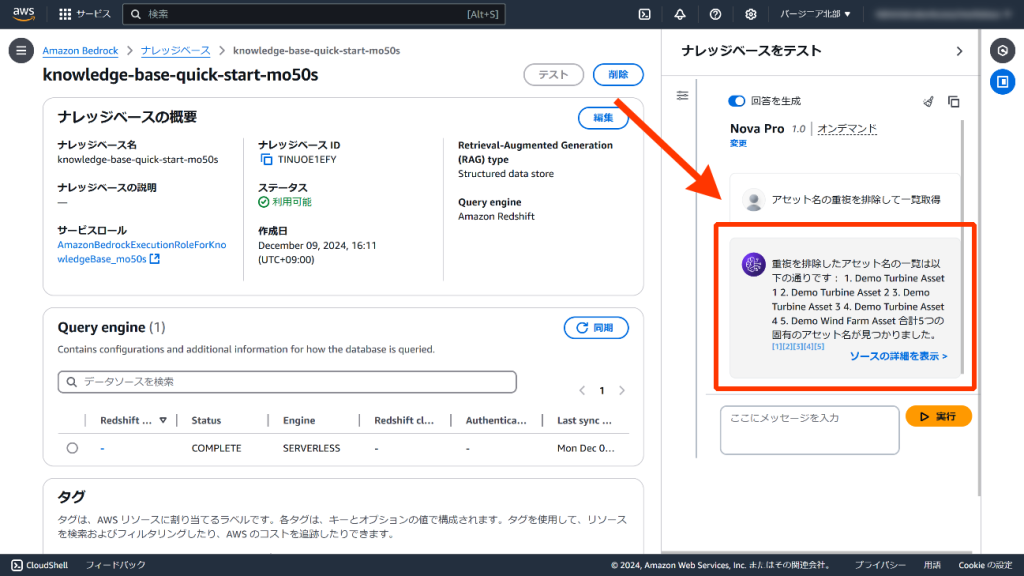
生成AIによる回答だけでなく、実行したSQLを確認することも可能です。今回は以下のSQLが作成されていました。
SELECT DISTINCT "assetname" FROM awsdatacatalog.windfarm.asset_metadata;「重複を排除して」の部分がSQLの“DISTINCT”に該当します。SQLを意識した自然言語で質問する必要がありそうです。
最後に「アセット名が'Demo Turbine Asset 1'の'Wind Speed'プロパティの最新の平均値は?」と質問したところ、正確な値が返答されました。
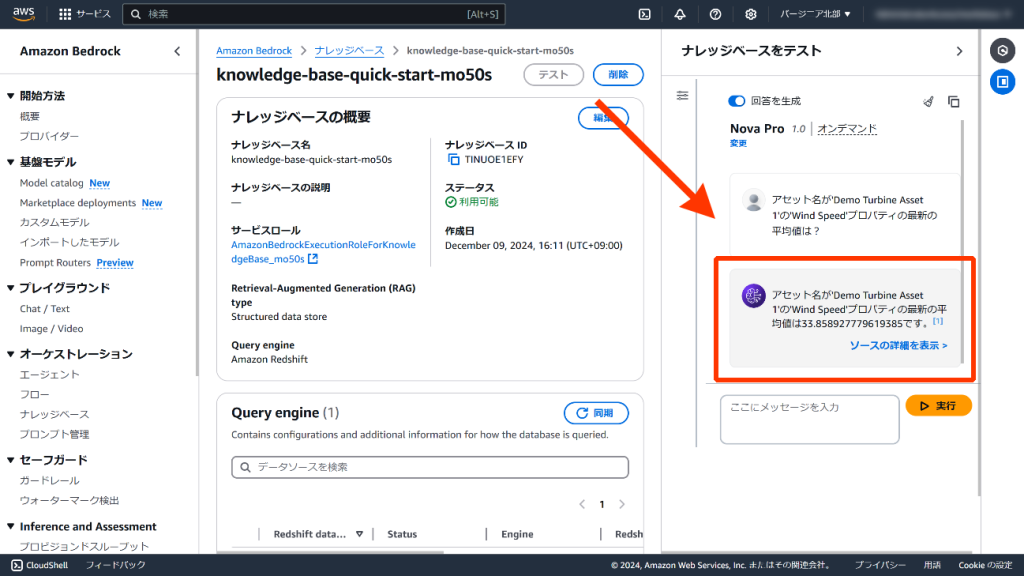
SQLは以下のとおりです。
SELECT "average" FROM awsdatacatalog.windfarm.agg WHERE "seriesid" = ( SELECT "timeseriesid" FROM awsdatacatalog.windfarm.asset_metadata WHERE "assetname" = 'Demo Turbine Asset 1' AND "assetpropertyname" = 'Wind Speed' ORDER BY "assetcreationdate" DESC LIMIT 1 ) ORDER BY "timeinseconds" DESC LIMIT 1;まとめ
今回はre:Invent 2024で発表されたAmazon Bedrockナレッジベースの新機能「structured data retrieval」を使ってIoTデータへの問い合わせを行いました。SQLを意識した自然言語で問いかける必要があるので、一般利用者が使うためには工夫が必要になる印象でした。
「AWS IoT TwinMakerとAmazon Bedrockを組み合わせた設備管理ソリューションの検証」で解説したトピック抽出の処理を前処理として挟むことで、より自由度の高い問い合わせが実現できそうだと感じました。




